Artificial Intelligence
KT’s journey to reduce training time for a vision transformers model using Amazon SageMaker
KT Corporation is one of the largest telecommunications providers in South Korea, offering a wide range of services including fixed-line telephone, mobile communication, and internet, and AI services. KT’s AI Food Tag is an AI-based dietary management solution that identifies the type and nutritional content of food in photos using a computer vision model. This vision model developed by KT relies on a model pre-trained with a large amount of unlabeled image data to analyze the nutritional content and calorie information of various foods. The AI Food Tag can help patients with chronic diseases such as diabetes manage their diets. KT used AWS and Amazon SageMaker to train this AI Food Tag model 29 times faster than before and optimize it for production deployment with a model distillation technique. In this post, we describe KT’s model development journey and success using SageMaker.
Introducing the KT project and defining the problem
The AI Food Tag model pre-trained by KT is based on the vision transformers (ViT) architecture and has more model parameters than their previous vision model to improve accuracy. To shrink the model size for production, KT is using a knowledge distillation (KD) technique to reduce the number of model parameters without significant impact to accuracy. With knowledge distillation, the pre-trained model is called a teacher model, and a lightweight output model is trained as a student model, as illustrated in the following figure. The lightweight student model has fewer model parameters than the teacher, which reduces memory requirements and allows for deployment on smaller, less expensive instances. The student maintains acceptable accuracy even though it’s smaller by learning from the outputs of the teacher model.
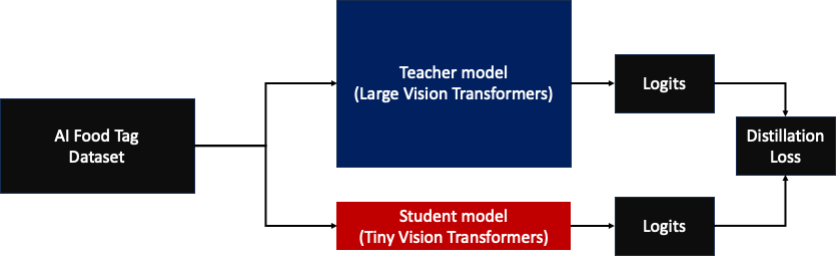
The teacher model remains unchanged during KD, but the student model is trained using the output logits of the teacher model as labels to calculate loss. With this KD paradigm, both the teacher and the student need to be on a single GPU memory for training. KT initially used two GPUs (A100 80 GB) in their internal, on-premises environment to train the student model, but the process took about 40 days to cover 300 epochs. To accelerate training and generate a student model in less time, KT partnered with AWS. Together, the teams significantly reduced model training time. This post describes how the team used Amazon SageMaker Training, the SageMaker Data Parallelism Library, Amazon SageMaker Debugger, and Amazon SageMaker Profiler to successfully develop a lightweight AI Food Tag model.
Building a distributed training environment with SageMaker
SageMaker Training is a managed machine learning (ML) training environment on AWS that provides a suite of features and tools to simplify the training experience and can be useful in distributed computing, as illustrated in the following diagram.
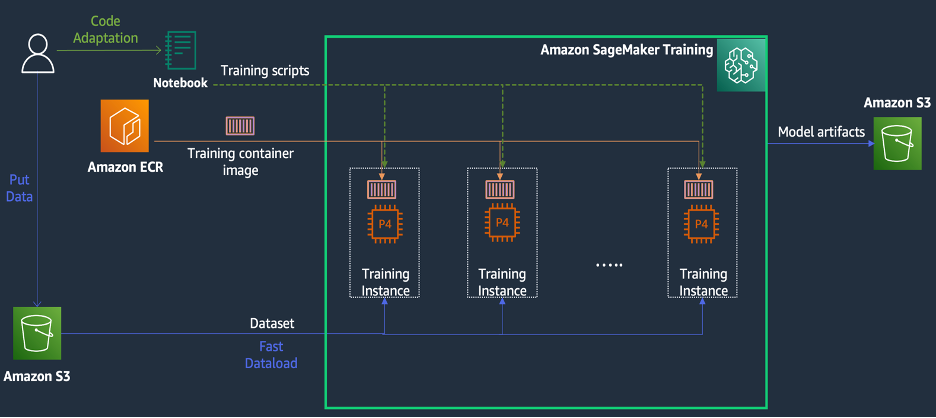
SageMaker customers can also access built-in Docker images with various pre-installed deep learning frameworks and the necessary Linux, NCCL, and Python packages for model training. Data scientists or ML engineers who want to run model training can do so without the burden of configuring training infrastructure or managing Docker and the compatibility of different libraries.
During a 1-day workshop, we were able to set up a distributed training configuration based on SageMaker within KT’s AWS account, accelerate KT’s training scripts using the SageMaker Distributed Data Parallel (DDP) library, and even test a training job using two ml.p4d.24xlarge instances. In this section, we describe KT’s experience working with the AWS team and using SageMaker to develop their model.
In the proof of concept, we wanted to speed up a training job by using the SageMaker DDP library, which is optimized for AWS infrastructure during distributed training. To change from PyTorch DDP to SageMaker DDP, you simply need to declare the torch_smddp package and change the backend to smddp, as shown in the following code:
To learn more about the SageMaker DDP library, refer to SageMaker’s Data Parallelism Library.
Analyzing the causes of slow training speed with the SageMaker Debugger and Profiler
The first step in optimizing and accelerating a training workload involves understanding and diagnosing where bottlenecks occur. For KT’s training job, we measured the training time per iteration of the data loader, forward pass, and backward pass:
| 1 iter time – dataloader : 0.00053 sec, forward : 7.77474 sec, backward: 1.58002 sec |
| 2 iter time – dataloader : 0.00063 sec, forward : 0.67429 sec, backward: 24.74539 sec |
| 3 iter time – dataloader : 0.00061 sec, forward : 0.90976 sec, backward: 8.31253 sec |
| 4 iter time – dataloader : 0.00060 sec, forward : 0.60958 sec, backward: 30.93830 sec |
| 5 iter time – dataloader : 0.00080 sec, forward : 0.83237 sec, backward: 8.41030 sec |
| 6 iter time – dataloader : 0.00067 sec, forward : 0.75715 sec, backward: 29.88415 sec |
Looking at the time in the standard output for each iteration, we saw that the backward pass’s run time fluctuated significantly from iteration to iteration. This variation is unusual and can impact total training time. To find the cause of this inconsistent training speed, we first tried to identify resource bottlenecks by utilizing the System Monitor (SageMaker Debugger UI), which allows you to debug training jobs on SageMaker Training and view the status of resources such as the managed training platform’s CPU, GPU, network, and I/O within a set number of seconds.
The SageMaker Debugger UI provides detailed and essential data that can help identifying and diagnose bottlenecks in a training job. Specifically, the CPU utilization line chart and CPU/GPU utilization heat map per instance tables caught our eye.
In the CPU utilization line chart, we noticed that some CPUs were being used 100%.

In the heat map (where darker colors indicate higher utilization), we noted that a few CPU cores had high utilization throughout the training, whereas GPU utilization wasn’t consistently high over time.

From here, we began to suspect that one of the reasons for the slow training speed was a CPU bottleneck. We reviewed the training script code to see if anything was causing the CPU bottleneck. The most suspicious part was the large value of num_workers in the data loader, so we changed this value to 0 or 1 to reduce CPU utilization. We then ran the training job again and checked the results.
The following screenshots show the CPU utilization line chart, GPU utilization, and heat map after mitigating the CPU bottleneck.
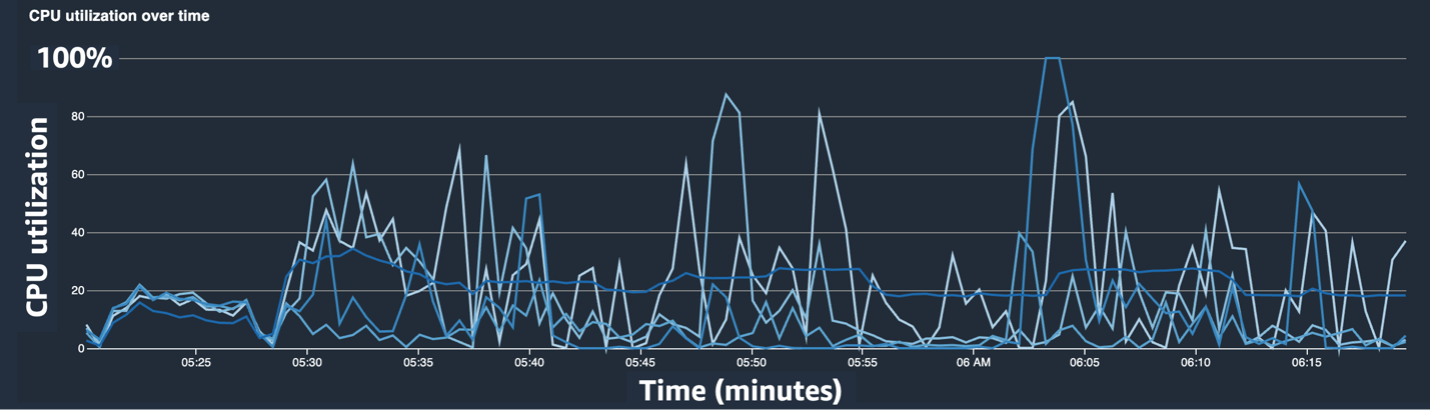


By simply changing num_workers, we saw a significant decrease in CPU utilization and an overall increase in GPU utilization. This was an important change that improved training speed significantly. Still, we wanted to see where we could optimize GPU utilization. For this, we used SageMaker Profiler.
SageMaker Profiler helps identify optimization clues by providing visibility into utilization by operations, including tracking GPU and CPU utilization metrics and kernel consumption of GPU/CPU within training scripts. It helps users understand which operations are consuming resources. First, to use SageMaker Profiler, you need to add ProfilerConfig to the function that invokes the training job using the SageMaker SDK, as shown in the following code:
In the SageMaker Python SDK, you have the flexibility to add the annotate functions for SageMaker Profiler to select code or steps in the training script that needs profiling. The following is an example of the code that you should declare for SageMaker Profiler in the training scripts:
After adding the preceding code, if you run a training job using the training scripts, you can get information about the operations consumed by the GPU kernel (as shown in the following figure) after the training runs for a period of time. In the case of KT’s training scripts, we ran it for one epoch and got the following results.
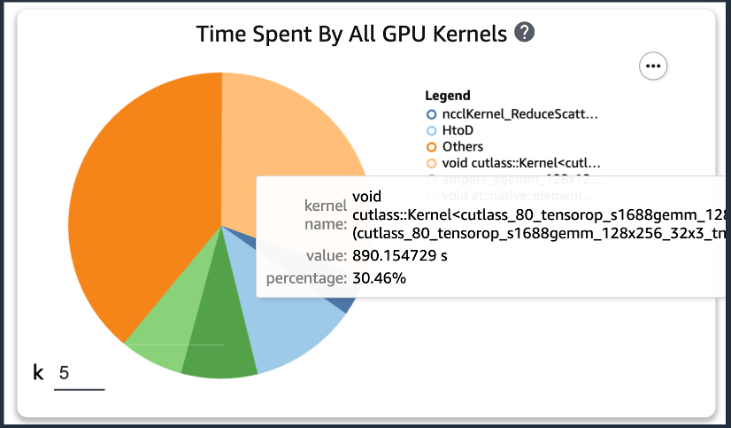
When we checked the top five operation consumption times of the GPU kernel among the results of SageMaker Profiler, we found that for the KT training script, the most time is consumed by the matrix product operation, which is a general matrix multiplication (GEMM) operation on GPUs. With this important insight from the SageMaker Profiler, we began investigating ways to accelerate these operations and improve GPU utilization.
Speeding up training time
We reviewed various ways to reduce computation time of matrix multiplication and applied two PyTorch functions.
Shard optimizer states with ZeroRedundancyOptimizer
If you look at the Zero Redundancy Optimizer (ZeRO), the DeepSpeed/ZeRO technique enables the training of a large model efficiently with better training speed by eliminating the redundancies in memory used by the model. ZeroRedundancyOptimizer in PyTorch uses the technique of sharding the optimizer state to reduce memory usage per a process in Distributed Data Parallel (DDP). DDP uses synchronized gradients in the backward pass so that all optimizer replicas iterate over the same parameters and gradient values, but instead of having all the model parameters, each optimizer state is maintained by sharding only for different DDP processes to reduce memory usage.
To use it, you can leave your existing Optimizer in optimizer_class and declare a ZeroRedundancyOptimizer with the rest of the model parameters and the learning rate as parameters.
Automatic mixed precision
Automatic mixed precision (AMP) uses the torch.float32 data type for some operations and torch.bfloat16 or torch.float16 for others, for the convenience of fast computation and reduced memory usage. In particular, because deep learning models are typically more sensitive to exponent bits than fraction bits in their computations, torch.bfloat16 is equivalent to the exponent bits of torch.float32, allowing them to learn quickly with minimal loss. torch.bfloat16 only runs on instances with A100 NVIDIA architecture (Ampere) or higher, such as ml.p4d.24xlarge, ml.p4de.24xlarge, and ml.p5.48xlarge.
To apply AMP, you can declare torch.cuda.amp.autocast in the training scripts as shown in the code above and declare dtype as torch.bfloat16.
Results in SageMaker Profiler
After applying the two functions to the training scripts and running a train job for one epoch again, we checked the top five operations consumption times for the GPU kernel in SageMaker Profiler. The following figure shows our results.
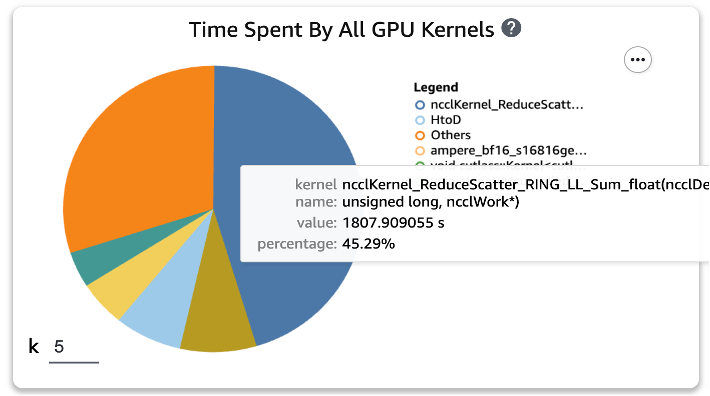
We can see that the GEMM operation, which was at the top of the list before applying the two Torch functions, has disappeared from the top five operations, replaced by the ReduceScatter operation, which typically occurs in distributed training.
Training speed results of the KT distilled model
We increased the training batch size by 128 more to account for the memory savings from applying the two Torch functions, resulting in a final batch size of 1152 instead of 1024. The training of the final student model was able to run 210 epochs per 1 day; the training time and speedup between KT’s internal training environment and SageMaker are summarized in the following table.
| Training Environment | Training GPU spec. | Number of GPU | Training Time (hours) | Epoch | Hours per Epoch | Reduction Ratio |
| KT’s internal training environment | A100 (80GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon SageMaker | A100 (40GB) | 32 | 24 | 210 | 0.11 | 1 |
The scalability of AWS allowed us to complete the training job 29 times faster than before using 32 GPUs instead of 2 on premises. As a result, using more GPUs on SageMaker would have significantly reduced training time with no difference in overall training costs.
Conclusion
Park Sang-min (Vision AI Serving Technology Team Leader) from the AI2XL Lab in KT’s Convergence Technology Center commented on the collaboration with AWS to develop the AI Food Tag model:
“Recently, as there are more transformer-based models in the vision field, the model parameters and required GPU memory are increasing. We are using lightweight technology to solve this issue, and it takes a lot of time, about a month to learn once. Through this PoC with AWS, we were able to identify the resource bottlenecks with help of SageMaker Profiler and Debugger, resolve them, and then use SageMaker’s data parallelism library to complete the training in about one day with optimized model code on four ml.p4d.24xlarge instances.”
SageMaker helped save Sang-min’s team weeks of time in model training and development.
Based on this collaboration on the vision model, AWS and the SageMaker team will continue to collaborate with KT on various AI/ML research projects to improve model development and service productivity through applying SageMaker capabilities.
To learn more about related features in SageMaker, check out the following:
- Train machine learning models
- SageMaker’s Data Parallelism Library
- Use Amazon SageMaker Debugger to debug and improve model performance
- Use Amazon SageMaker Profiler to profile activities on AWS compute resources
About the authors
 Youngjoon Choi, AI/ML Expert SA, has experienced enterprise IT in various industries such as manufacturing, high-tech, and finance as a developer, architect, and data scientist. He conducted research on machine learning and deep learning, specifically on topics like hyperparameter optimization and domain adaptation, presenting algorithms and papers. At AWS, he specializes in AI/ML across industries, providing technical validation using AWS services for distributed training/large scale models and building MLOps. He proposes and reviews architectures, aiming to contribute to the expansion of the AI/ML ecosystem.
Youngjoon Choi, AI/ML Expert SA, has experienced enterprise IT in various industries such as manufacturing, high-tech, and finance as a developer, architect, and data scientist. He conducted research on machine learning and deep learning, specifically on topics like hyperparameter optimization and domain adaptation, presenting algorithms and papers. At AWS, he specializes in AI/ML across industries, providing technical validation using AWS services for distributed training/large scale models and building MLOps. He proposes and reviews architectures, aiming to contribute to the expansion of the AI/ML ecosystem.
 Jung Hoon Kim is an account SA of AWS Korea. Based on experiences in applications architecture design, development and systems modeling in various industries such as hi-tech, manufacturing, finance and public sector, he is working on AWS Cloud journey and workloads optimization on AWS for enterprise customers.
Jung Hoon Kim is an account SA of AWS Korea. Based on experiences in applications architecture design, development and systems modeling in various industries such as hi-tech, manufacturing, finance and public sector, he is working on AWS Cloud journey and workloads optimization on AWS for enterprise customers.
 Rock Sakong is a researcher at KT R&D. He has conducted research and development for the vision AI in various fields and mainly conducted facial attributes (gender/glasses, hats, etc.)/face recognition technology related to the face. Currently, he is working on lightweight technology for the vision models.
Rock Sakong is a researcher at KT R&D. He has conducted research and development for the vision AI in various fields and mainly conducted facial attributes (gender/glasses, hats, etc.)/face recognition technology related to the face. Currently, he is working on lightweight technology for the vision models.
 Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.
Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.
 Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads frameworks, compilers, and optimization techniques for deep learning training.
Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads frameworks, compilers, and optimization techniques for deep learning training.