Artificial Intelligence
Enhance Amazon Lex with conversational FAQ features using LLMs
Amazon Lex is a service that allows you to quickly and easily build conversational bots (“chatbots”), virtual agents, and interactive voice response (IVR) systems for applications such as Amazon Connect.
Artificial intelligence (AI) and machine learning (ML) have been a focus for Amazon for over 20 years, and many of the capabilities that customers use with Amazon are driven by ML. Today, large language models (LLMs) are transforming the way developers and enterprises solve historically complex challenges related to natural language understanding (NLU). We announced Amazon Bedrock recently, which democratizes Foundational Model access for developers to easily build and scale generative AI-based applications, using familiar AWS tools and capabilities. One of the challenges enterprises face is to incorporate their business knowledge into LLMs to deliver accurate and relevant responses. When leveraged effectively, enterprise knowledge bases can be used to deliver tailored self-service and assisted-service experiences, by delivering information that helps customers solve problems independently and/or augmenting an agent’s knowledge. Today, a bot developer can improve self-service experiences without utilizing LLMs in a couple of ways. First, by creating intents, sample utterances, and responses, thereby covering all anticipated user questions within an Amazon Lex bot. Second, developers can also integrate bots with search solutions, which can index documents stored across a wide range of repositories and find the most relevant document to answer their customer’s question. These methods are effective, but require developer resources making getting started difficult.
One of the benefits offered by LLMs is the ability to create relevant and compelling conversational self-service experiences. They do so by leveraging enterprise knowledge base(s) and delivering more accurate and contextual responses. This blog post introduces a powerful solution for augmenting Amazon Lex with LLM-based FAQ features using the Retrieval Augmented Generation (RAG). We will review how the RAG approach augments Amazon Lex FAQ responses using your company data sources. In addition, we will also demonstrate Amazon Lex integration with LlamaIndex, which is an open-source data framework that provides knowledge source and format flexibility to the bot developer. As a bot developer gains confidence with using a LlamaIndex to explore LLM integration, they can scale the Amazon Lex capability further. They can also use enterprise search services such as Amazon Kendra, which is natively integrated with Amazon Lex.
In this solution, we showcase the practical application of an Amazon Lex chatbot with LLM-based RAG enhancement. We use the Zappos customer support use case as an example to demonstrate the effectiveness of this solution, which takes the user through an enhanced FAQ experience (with LLM), rather than directing them to fallback (default, without LLM).
Solution overview
RAG combines the strengths of traditional retrieval-based and generative AI based approaches to Q&A systems. This methodology harnesses the power of large language models, such as Amazon Titan or open-source models (for example, Falcon), to perform generative tasks in retrieval systems. It also takes into account the semantic context from stored documents more effectively and efficiently.
RAG starts with an initial retrieval step to retrieve relevant documents from a collection based on the user’s query. It then employs a language model to generate a response by considering both the retrieved documents and the original query. By integrating RAG into Amazon Lex, we can provide accurate and comprehensive answers to user queries, resulting in a more engaging and satisfying user experience.
The RAG approach requires document ingestion so that embeddings can be created to enable LLM-based search. The following diagram shows how the ingestion process creates the embeddings that are then used by the chatbot during fallback to answer the customer’s question.
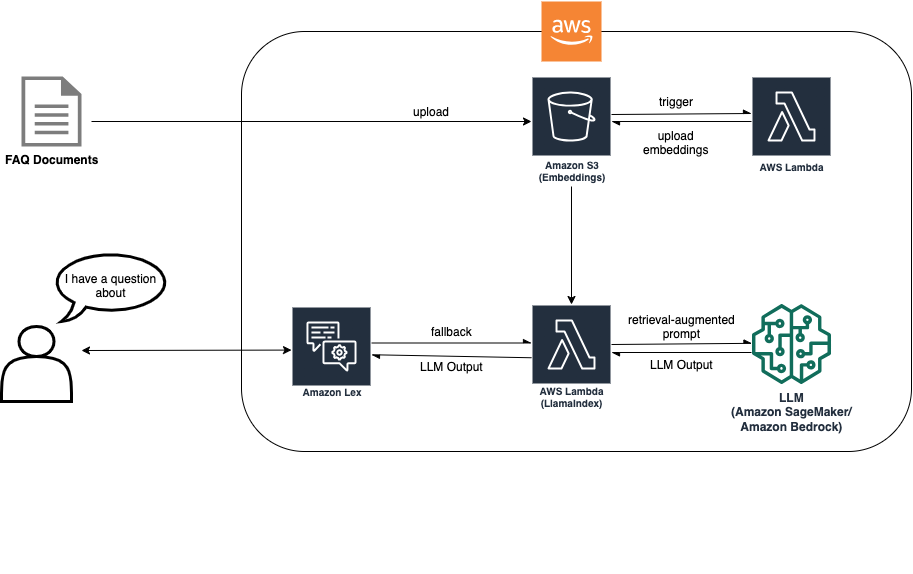
With this solution architecture, you should choose the most suitable LLM for your use case. It also provides an inference endpoint choice between Amazon Bedrock (in limited preview) and models hosted on Amazon SageMaker JumpStart, offering additional LLM flexibility.
The document is uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The S3 bucket has an event listener attached that invokes an AWS Lambda function on changes to the bucket. The event listener ingests the new document and places the embeddings in another S3 bucket. The embeddings are then used by the RAG implementation in the Amazon Lex bot during the fallback intent to answer the customer’s question. The next diagram shows the architecture of how an FAQ bot within Lex can be enhanced with LLMs and RAG.
Let’s explore how we can integrate RAG based on LlamaIndex into an Amazon Lex bot. We provide code examples and an AWS Cloud Development Kit (AWS CDK) import to assist you in setting up the integration. You can find the code examples in our GitHub repository. The following sections provide a step-by-step guide to help you set up the environment and deploy the necessary resources.
How RAG works with Amazon Lex
The flow of RAG involves an iterative process where the retriever component retrieves relevant passages, the question and passages help construct the prompt, and the generation component produces a response. This combination of retrieval and generation techniques allows the RAG model to take advantage of the strengths of both approaches, providing accurate and contextually appropriate answers to user questions. The workflow provides the following capabilities:
- Retriever engine – The RAG model begins with a retriever component responsible for retrieving relevant documents from a large corpus. This component typically uses an information retrieval technique like TF-IDF or BM25 to rank and select documents that are likely to contain the answer to a given question. The retriever scans the document corpus and retrieves a set of relevant passages.
- Prompt helper – After the retriever has identified the relevant passages, the RAG model moves to prompt creation. The prompt is a combination of the question and the retrieved passages, serving as additional context for the prompt, which is used as input to the generator component. To create the prompt, the model typically augments the question with the selected passages in a specific format.
- Response generation – The prompt, consisting of the question and relevant passages, is fed into the generation component of the RAG model. The generation component is usually a language model capable of reasoning through the prompt to generate a coherent and relevant response.
- Final response – Finally, the RAG model selects the highest-ranked answer as the output and presents it as the response to the original question. The selected answer can be further postprocessed or formatted as necessary before being returned to the user. In addition, the solution enables the filtering of the generated response if the retrieval results yields a low confidence score, implying that it likely falls outside the distribution (OOD).
LlamaIndex: An open-source data framework for LLM-based applications
In this post, we demonstrate the RAG solution based on LlamaIndex. LlamaIndex is an open-source data framework specifically designed to facilitate LLM-based applications. It offers a robust and scalable solution for managing document collection in different formats. With LlamaIndex, bot developers are empowered to effortlessly integrate LLM-based QA (question answering) capabilities into their applications, eliminating the complexities associated with managing solutions catered to large-scale document collections. Furthermore, this approach proves to be cost-effective for smaller-sized document repositories.
Prerequisites
You should have the following prerequisites:
- An AWS account
- An AWS Identity and Access Management (IAM) user and role permissions to access the following:
- Amazon Lex
- Lambda
- Amazon SageMaker
- An S3 bucket
- The AWS CDK installed
Set up your development environment
The main third-party package requirements are llama_index and sagemaker sdk. Follow the specified commands in our GitHub repository’s README to set up your environment properly.
Deploy the required resources
This step involves creating an Amazon Lex bot, S3 buckets, and a SageMaker endpoint. Additionally, you need to Dockerize the code in the Docker image directory and push the images to Amazon Elastic Container Registry (Amazon ECR) so that it can run in Lambda. Follow the specified commands in our GitHub repository’s README to deploy the services.
During this step, we demonstrate LLM hosting via SageMaker Deep Learning Containers. Adjust the settings according to your computation needs:
- Model – To find a model that meets your requirements, you can explore resources like the Hugging Face model hub. It offers a variety of models such as Falcon 7B or Flan-T5-XXL. Additionally, you can find detailed information about various officially supported model architectures, helping you make an informed decision. For more information about different model types, refer to optimized architectures.
- Model inference endpoint – Define the path of the model (for example, Falcon 7B), choose your instance type (for example, g5.4xlarge), and use quantization (for example, int-8 quantization).Note: This solution provides you the flexibility to choose another model inferencing endpoint. You can also use Amazon Bedrock, which provides access to other LLMs such as Amazon Titan.Note: This solution provides you the flexibility to choose another model inferencing endpoint. You can also use Amazon Bedrock, which provides access to other LLMs such as Amazon Titan.
Set up your document index via LlamaIndex
To set up your document index, first upload your document data. We assume that you have the source of your FAQ content, such as a PDF or text file.
After the document data is uploaded, the LlamaIndex system will automatically initiate the process of creating the document index. This task is performed by a Lambda function, which generates the index and saves it to an S3 bucket.
To enable efficient retrieval of relevant information, configure the document retriever using the LlamaIndex Retriever Query Engine. This engine offers several customization options, such as the following:
- Embedding models – You can choose your embedding model, such as Hugging Face embedding.
- Confidence cutoff – Specify a confidence cutoff threshold to determine the quality of retrieval results. If the confidence score falls below this threshold, you can choose to provide out-of-scope responses, indicating that the query is beyond the scope of the indexed documents.
Test the integration
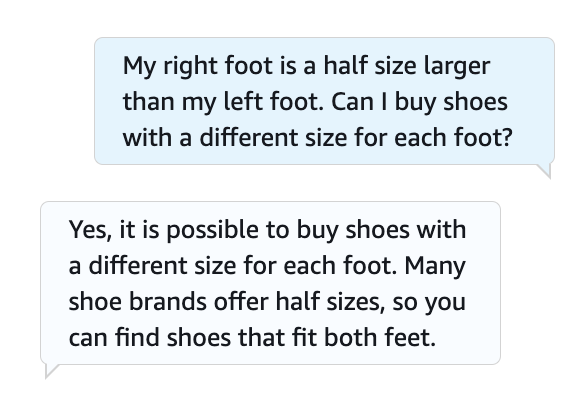
Define your bot definition with a fallback intent and use the Amazon Lex console to test your FAQ requests. For more details, please refer to GitHub repository. The following screenshot shows an example conversation with the bot.

Tips to boost your bot efficiency
The following tips could potentially further improve the efficiency of your bot:
- Index storage – Store your index in an S3 bucket or a service with vector database capabilities such as Amazon OpenSearch. By utilizing cloud-based storage solutions, you can enhance the accessibility and scalability of your index, leading to faster retrieval times and improved overall performance. Also, Refer to this blog post for an Amazon Lex bot that utilizes an Amazon Kendra search solution.
- Retrieval optimization – Experiment with different sizes of embedding models for the retriever. The choice of embedding model can significantly impact the input requirements of your LLM. Finding the optimal balance between model size and retrieval performance can result in improved efficiency and faster response times.
- Prompt engineering – Experiment with different prompt formats, lengths, and styles to optimize the performance and quality of your bot’s answers.
- LLM model selection – Select the most suitable LLM model for your specific use case. Consider factors such as model size, language capabilities, and compatibility with your application requirements. Choosing the right LLM model ensures optimal performance and efficient utilization of system resources.
Contact center conversations can span from self-service to a live human interaction. For use cases involving human-to-human interactions over Amazon Connect, you can use Wisdom to search and find content across multiple repositories, such as frequently asked questions (FAQs), wikis, articles, and step-by-step instructions for handling different customer issues.
Clean up
To avoid incurring future expenses, proceed with deleting all the resources that were deployed as part of this exercise. We have provided a script to shut down the SageMaker endpoint gracefully. Usage details are in the README. Additionally, to remove all the other resources you can run cdk destroy in the same directory as the other cdk commands to deprovision all the resources in your stack.
Summary
This post discussed the following steps to enhance Amazon Lex with LLM-based QA features using the RAG strategy and LlamaIndex:
- Install the necessary dependencies, including LlamaIndex libraries
- Set up model hosting via Amazon SageMaker or Amazon Bedrock (in limited preview)
- Configure LlamaIndex by creating an index and populating it with relevant documents
- Integrate RAG into Amazon Lex by modifying the configuration and configuring RAG to use LlamaIndex for document retrieval
- Test the integration by engaging in conversations with the chatbot and observing its retrieval and generation of accurate responses
By following these steps, you can seamlessly incorporate powerful LLM-based QA capabilities and efficient document indexing into your Amazon Lex chatbot, resulting in more accurate, comprehensive, and contextually aware interactions with users. As a follow up, we also invite you to review our next blog post, which explores enhancing the Amazon Lex FAQ experience using URL ingestion and LLMs.
About the authors
 Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking.
Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking.
 Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data.
Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data.
 Saket Saurabh is an engineer with AWS Lex team. He works on improving Lex developer experience to help developers build more human-like chat bots. Outside of work, he enjoys traveling, discovering diverse cuisines, and learn about different cultures.
Saket Saurabh is an engineer with AWS Lex team. He works on improving Lex developer experience to help developers build more human-like chat bots. Outside of work, he enjoys traveling, discovering diverse cuisines, and learn about different cultures.