Artificial Intelligence
Category: Technical How-to
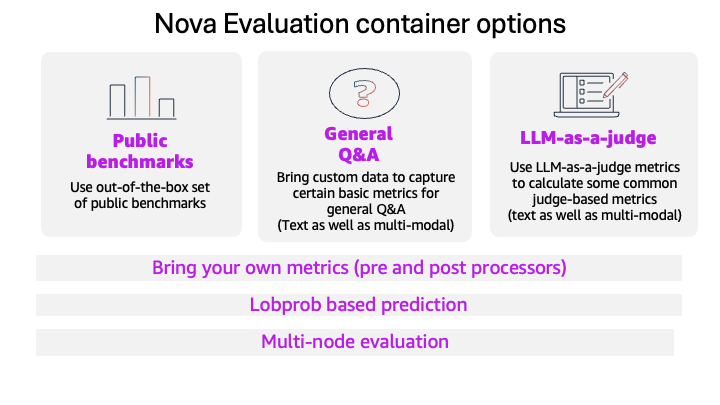
Evaluate models with the Amazon Nova evaluation container using Amazon SageMaker AI
This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations.
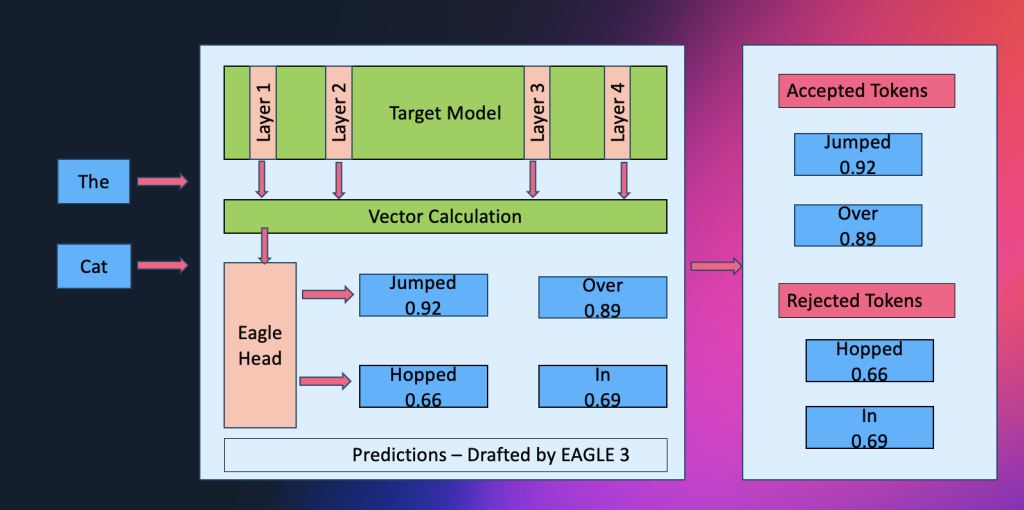
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference
Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency.
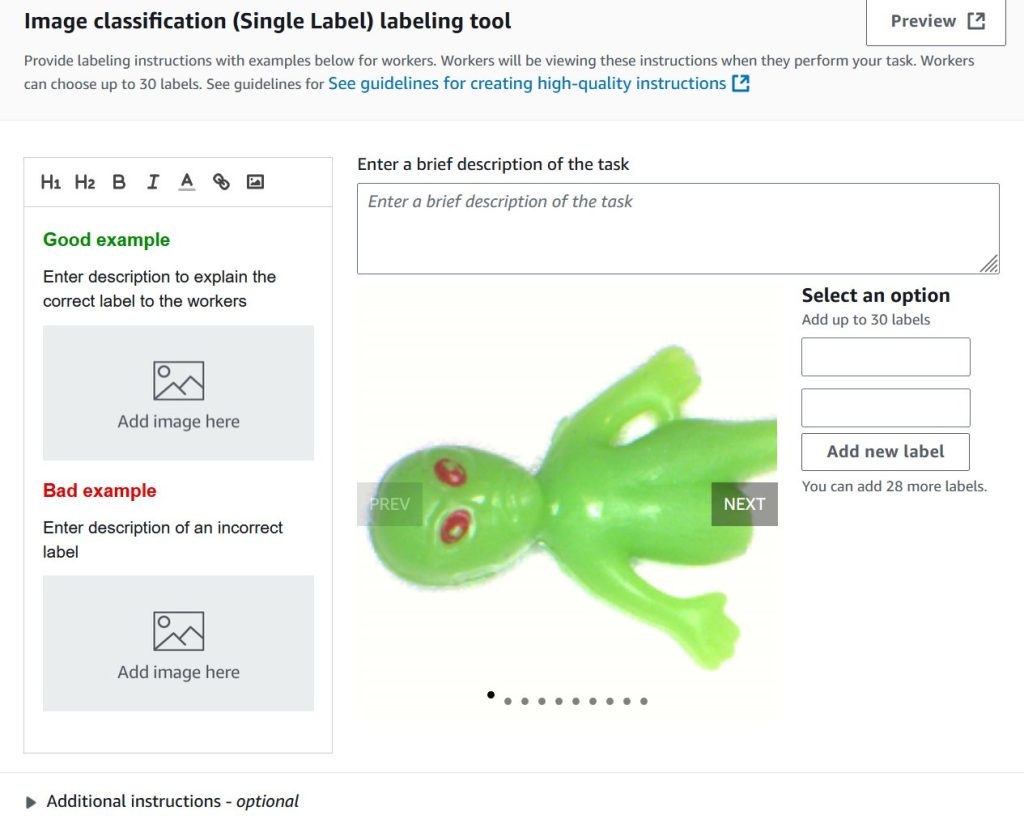
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.

Introducing bidirectional streaming for real-time inference on Amazon SageMaker AI
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference.
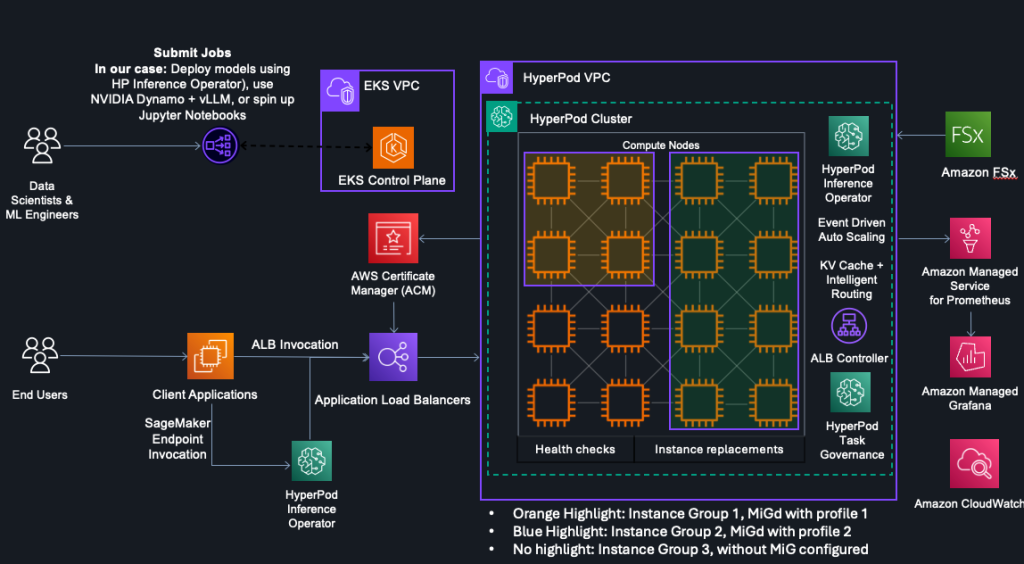
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

Power up your ML workflows with interactive IDEs on SageMaker HyperPod
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.
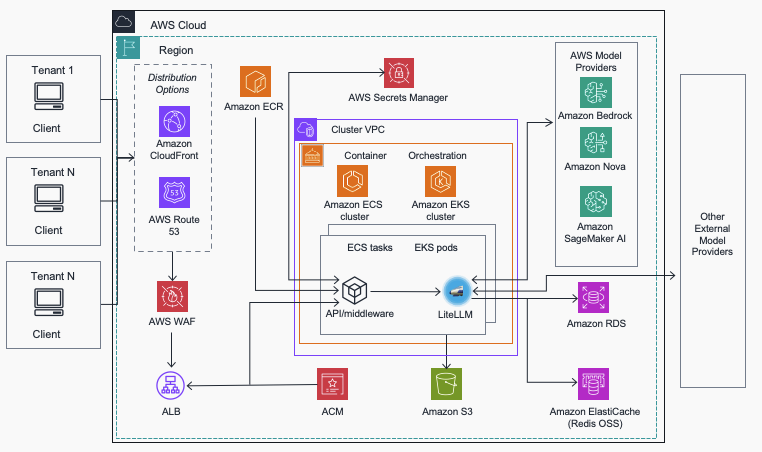
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architecture
In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities.

Claude Code deployment patterns and best practices with Amazon Bedrock
In this post, we explore deployment patterns and best practices for Claude Code with Amazon Bedrock, covering authentication methods, infrastructure decisions, and monitoring strategies to help enterprises deploy securely at scale. We recommend using Direct IdP integration for authentication, a dedicated AWS account for infrastructure, and OpenTelemetry with CloudWatch dashboards for comprehensive monitoring to ensure secure access, capacity management, and visibility into costs and developer productivity .
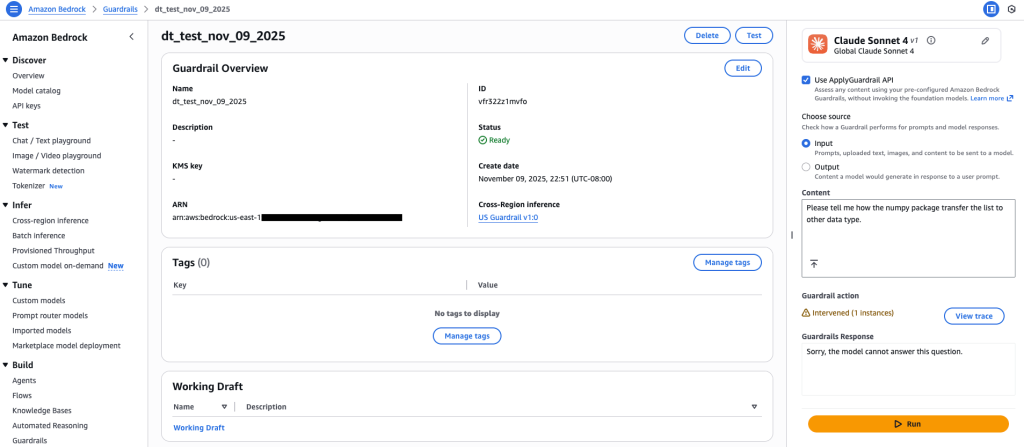
Amazon Bedrock Guardrails expands support for code domain
Amazon Bedrock Guardrails now extends its safety controls to protect code generation across twelve programming languages, addressing critical security challenges in AI-assisted software development. In this post, we explore how to configure content filters, prompt attack detection, denied topics, and sensitive information filters to safeguard against threats like prompt injection, data exfiltration, and malicious code generation while maintaining developer productivity .
Build an agentic solution with Amazon Nova, Snowflake, and LangGraph
In this post, we cover how you can use tools from Snowflake AI Data Cloud and Amazon Web Services (AWS) to build generative AI solutions that organizations can use to make data-driven decisions, increase operational efficiency, and ultimately gain a competitive edge.