Artificial Intelligence
Category: Amazon CloudWatch
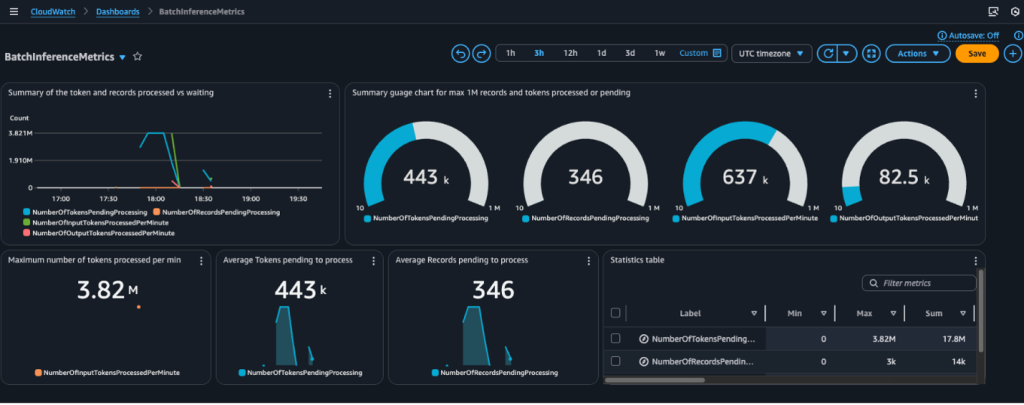
Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
In this post, we explore how to monitor and manage Amazon Bedrock batch inference jobs using Amazon CloudWatch metrics, alarms, and dashboards to optimize performance, cost, and operational efficiency.

Advancing AI agent governance with Boomi and AWS: A unified approach to observability and compliance
In this post, we share how Boomi partnered with AWS to help enterprises accelerate and scale AI adoption with confidence using Agent Control Tower.

Innovating at speed: BMW’s generative AI solution for cloud incident analysis
In this post, we explain how BMW uses generative AI to speed up the root cause analysis of incidents in complex and distributed systems in the cloud such as BMW’s Connected Vehicle backend serving 23 million vehicles. Read on to learn how the solution, collaboratively pioneered by AWS and BMW, uses Amazon Bedrock Agents and Amazon CloudWatch logs and metrics to find root causes quicker. This post is intended for cloud solution architects and developers interested in speeding up their incident workflows.

How Formula 1® uses generative AI to accelerate race-day issue resolution
In this post, we explain how F1 and AWS have developed a root cause analysis (RCA) assistant powered by Amazon Bedrock to reduce manual intervention and accelerate the resolution of recurrent operational issues during races from weeks to minutes. The RCA assistant enables the F1 team to spend more time on innovation and improving its services, ultimately delivering an exceptional experience for fans and partners. The successful collaboration between F1 and AWS showcases the transformative potential of generative AI in empowering teams to accomplish more in less time.

Governing the ML lifecycle at scale: Centralized observability with Amazon SageMaker and Amazon CloudWatch
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker. A multi-account strategy is essential not only for improving governance but also for enhancing […]

Detect and protect sensitive data with Amazon Lex and Amazon CloudWatch Logs
In today’s digital landscape, the protection of personally identifiable information (PII) is not just a regulatory requirement, but a cornerstone of consumer trust and business integrity. Organizations use advanced natural language detection services like Amazon Lex for building conversational interfaces and Amazon CloudWatch for monitoring and analyzing operational data. One risk many organizations face is […]

The Weather Company enhances MLOps with Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch
In this post, we share the story of how The Weather Company (TWCo) enhanced its MLOps platform using services such as Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch. TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. TWCo reduced infrastructure management time by 90% while also reducing model deployment time by 20%.

Identify idle endpoints in Amazon SageMaker
Amazon SageMaker is a machine learning (ML) platform designed to simplify the process of building, training, deploying, and managing ML models at scale. With a comprehensive suite of tools and services, SageMaker offers developers and data scientists the resources they need to accelerate the development and deployment of ML solutions. In today’s fast-paced technological landscape, […]

Improve visibility into Amazon Bedrock usage and performance with Amazon CloudWatch
In this blog post, we will share some of capabilities to help you get quick and easy visibility into Amazon Bedrock workloads in context of your broader application. We will use the contextual conversational assistant example in the Amazon Bedrock GitHub repository to provide examples of how you can customize these views to further enhance visibility, tailored to your use case. Specifically, we will describe how you can use the new automatic dashboard in Amazon CloudWatch to get a single pane of glass visibility into the usage and performance of Amazon Bedrock models and gain end-to-end visibility by customizing dashboards with widgets that provide visibility and insights into components and operations such as Retrieval Augmented Generation in your application.

How LotteON built dynamic A/B testing for their personalized recommendation system
This post is co-written with HyeKyung Yang, Jieun Lim, and SeungBum Shim from LotteON. LotteON is transforming itself into an online shopping platform that provides customers with an unprecedented shopping experience based on its in-store and online shopping expertise. Rather than simply selling the product, they create and let customers experience the product through their […]