Artificial Intelligence
Category: Advanced (300)

Responsible AI in action: How Data Reply red teaming supports generative AI safety on AWS
In this post, we explore how AWS services can be seamlessly integrated with open source tools to help establish a robust red teaming mechanism within your organization. Specifically, we discuss Data Reply’s red teaming solution, a comprehensive blueprint to enhance AI safety and responsible AI practices.

Evaluate Amazon Bedrock Agents with Ragas and LLM-as-a-judge
In this post, we introduced the Open Source Bedrock Agent Evaluation framework, a Langfuse-integrated solution that streamlines the agent development process. We demonstrated how this evaluation framework can be integrated with pharmaceutical research agents. We used it to evaluate agent performance against biomarker questions and sent traces to Langfuse to view evaluation metrics across question types.

Amazon Bedrock Prompt Optimization Drives LLM Applications Innovation for Yuewen Group
Today, we are excited to announce the availability of Prompt Optimization on Amazon Bedrock. With this capability, you can now optimize your prompts for several use cases with a single API call or a click of a button on the Amazon Bedrock console. In this blog post, we discuss how Prompt Optimization improves the performance of large language models (LLMs) for intelligent text processing task in Yuewen Group.

Build an automated generative AI solution evaluation pipeline with Amazon Nova
In this post, we explore the importance of evaluating LLMs in the context of generative AI applications, highlighting the challenges posed by issues like hallucinations and biases. We introduced a comprehensive solution using AWS services to automate the evaluation process, allowing for continuous monitoring and assessment of LLM performance. By using tools like the FMeval Library, Ragas, LLMeter, and Step Functions, the solution provides flexibility and scalability, meeting the evolving needs of LLM consumers.

Build a FinOps agent using Amazon Bedrock with multi-agent capability and Amazon Nova as the foundation model
In this post, we use the multi-agent feature of Amazon Bedrock to demonstrate a powerful and innovative approach to AWS cost management. By using the advanced capabilities of Amazon Nova FMs, we’ve developed a solution that showcases how AI-driven agents can revolutionize the way organizations analyze, optimize, and manage their AWS costs.

Build multi-agent systems with LangGraph and Amazon Bedrock
This post demonstrates how to integrate open-source multi-agent framework, LangGraph, with Amazon Bedrock. It explains how to use LangGraph and Amazon Bedrock to build powerful, interactive multi-agent applications that use graph-based orchestration.
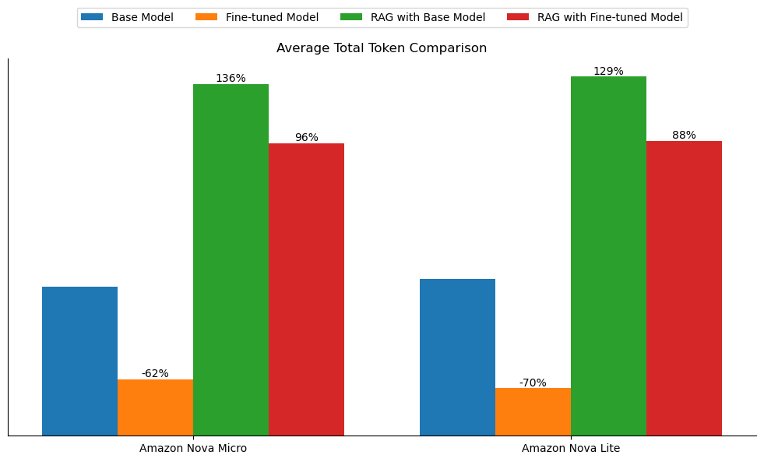
Model customization, RAG, or both: A case study with Amazon Nova
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for large language model (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. We conducted a comprehensive comparison study between model customization and RAG using the latest Amazon Nova models, and share these valuable insights.

Boost team productivity with Amazon Q Business Insights
In this post, we explore Amazon Q Business Insights capabilities and its importance for organizations. We begin with an overview of the available metrics and how they can be used for measuring user engagement and system effectiveness. Then we provide instructions for accessing and navigating this dashboard.

Multi-LLM routing strategies for generative AI applications on AWS
Organizations are increasingly using multiple large language models (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. The multi-LLM approach enables organizations to effectively choose the right model for each task, adapt to different […]

How iFood built a platform to run hundreds of machine learning models with Amazon SageMaker Inference
In this post, we show how iFood uses SageMaker to revolutionize its ML operations. By harnessing the power of SageMaker, iFood streamlines the entire ML lifecycle, from model training to deployment. This integration not only simplifies complex processes but also automates critical tasks.