Artificial Intelligence
Category: Database
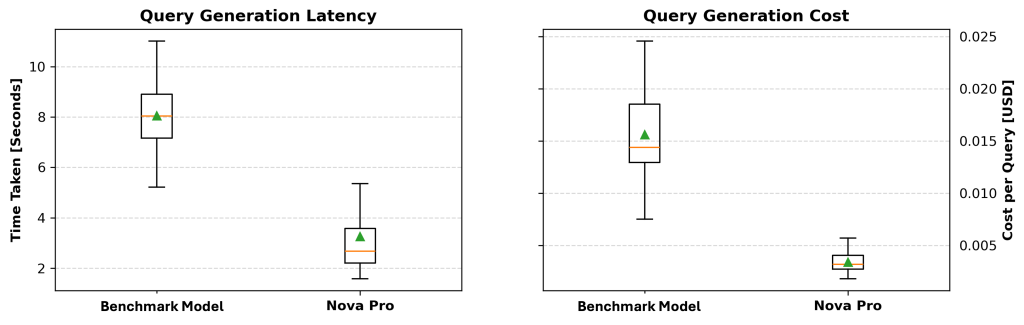
Generate Gremlin queries using Amazon Bedrock models
In this post, we explore an innovative approach that converts natural language to Gremlin queries using Amazon Bedrock models such as Amazon Nova Pro, helping business analysts and data scientists access graph databases without requiring deep technical expertise. The methodology involves three key steps: extracting graph knowledge, structuring the graph similar to text-to-SQL processing, and generating executable Gremlin queries through an iterative refinement process that achieved 74.17% overall accuracy in testing.
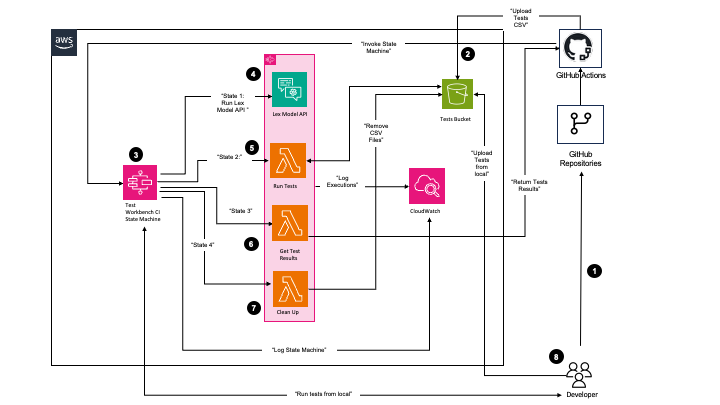
Principal Financial Group accelerates build, test, and deployment of Amazon Lex V2 bots through automation
In the post Principal Financial Group increases Voice Virtual Assistant performance using Genesys, Amazon Lex, and Amazon QuickSight, we discussed the overall Principal Virtual Assistant solution using Genesys Cloud, Amazon Lex V2, multiple AWS services, and a custom reporting and analytics solution using Amazon QuickSight.

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
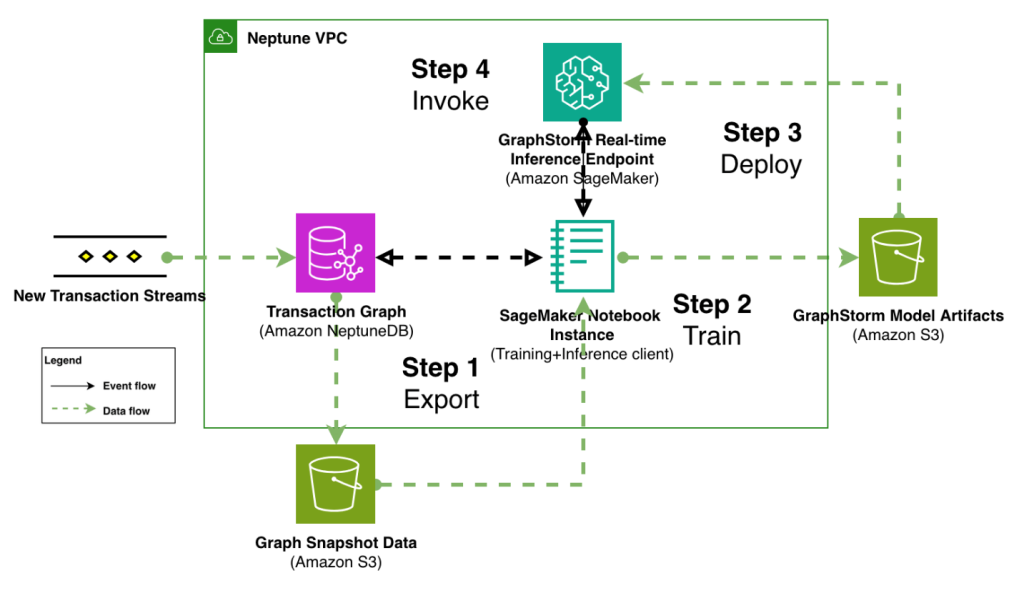
Modernize fraud prevention: GraphStorm v0.5 for real-time inference
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5’s new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with minimal operational overhead, enabling sub-second fraud detection on transaction graphs with billions of nodes and edges.
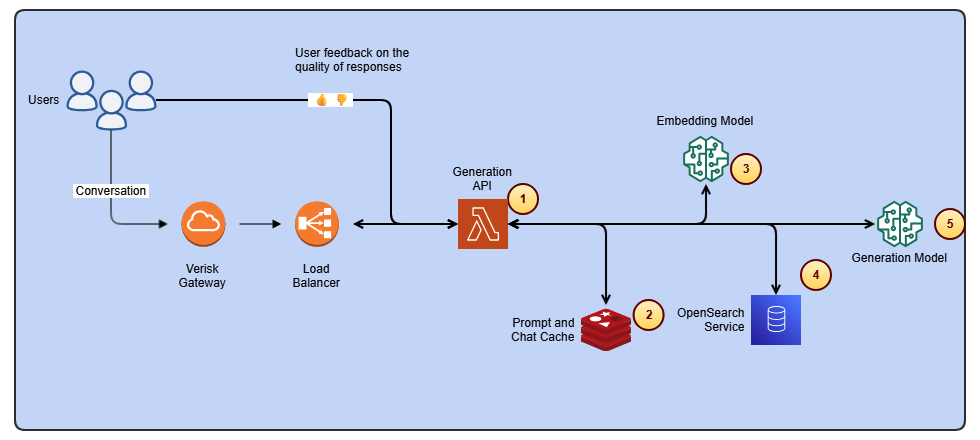
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.
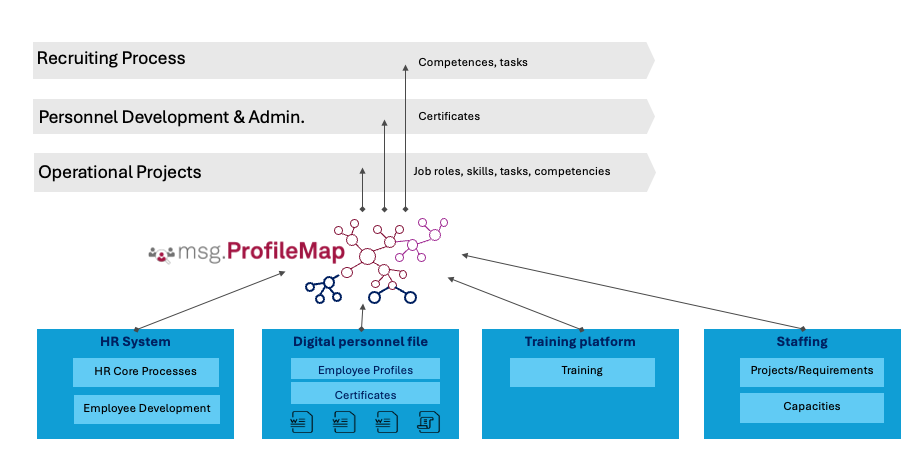
How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap
In this post, we share how msg automated data harmonization for msg.ProfileMap, using Amazon Bedrock to power its large language model (LLM)-driven data enrichment workflows, resulting in higher accuracy in HR concept matching, reduced manual workload, and improved alignment with compliance requirements under the EU AI Act and GDPR.
The power of AI in driving personalized product discovery at Snoonu
In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization. In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains you can realize by using Amazon Q Developer as a coding assistant to build a scalable MERN stack web application on AWS.

Build a conversational data assistant, Part 1: Text-to-SQL with Amazon Bedrock Agents
In this post, we focus on building a Text-to-SQL solution with Amazon Bedrock, a managed service for building generative AI applications. Specifically, we demonstrate the capabilities of Amazon Bedrock Agents. Part 2 explains how we extended the solution to provide business insights using Amazon Q in QuickSight, a business intelligence assistant that answers questions with auto-generated visualizations.

Query Amazon Aurora PostgreSQL using Amazon Bedrock Knowledge Bases structured data
In this post, we discuss how to make your Amazon Aurora PostgreSQL-Compatible Edition data available for natural language querying through Amazon Bedrock Knowledge Bases while maintaining data freshness.