Artificial Intelligence
Category: Amazon SageMaker HyperPod
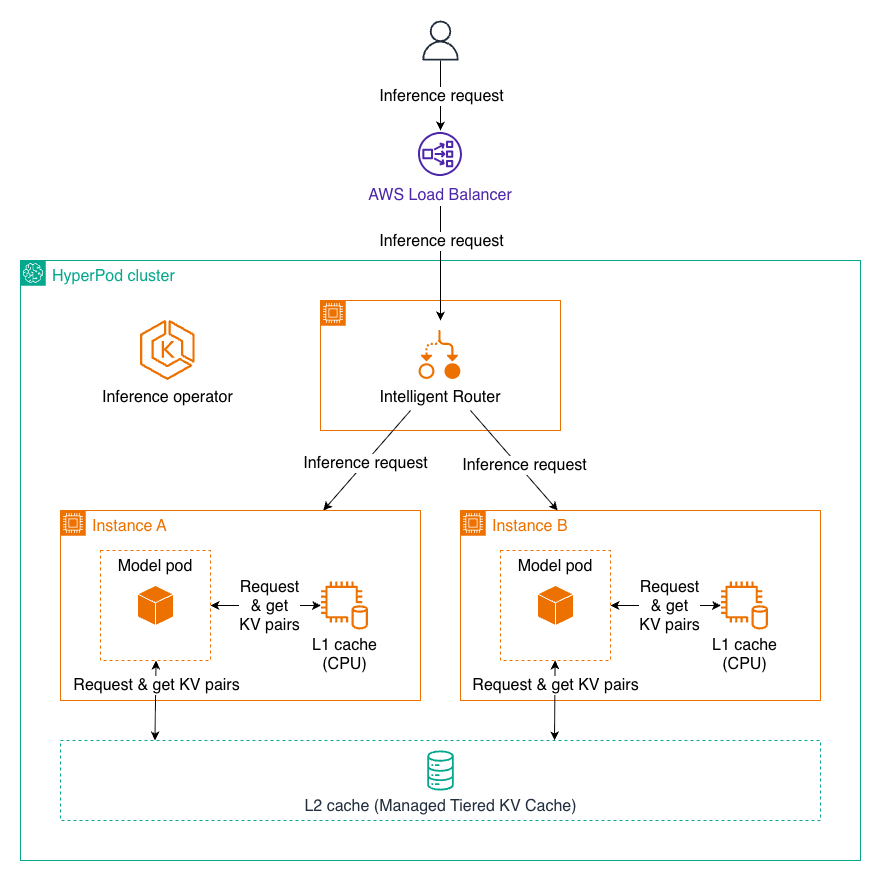
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.
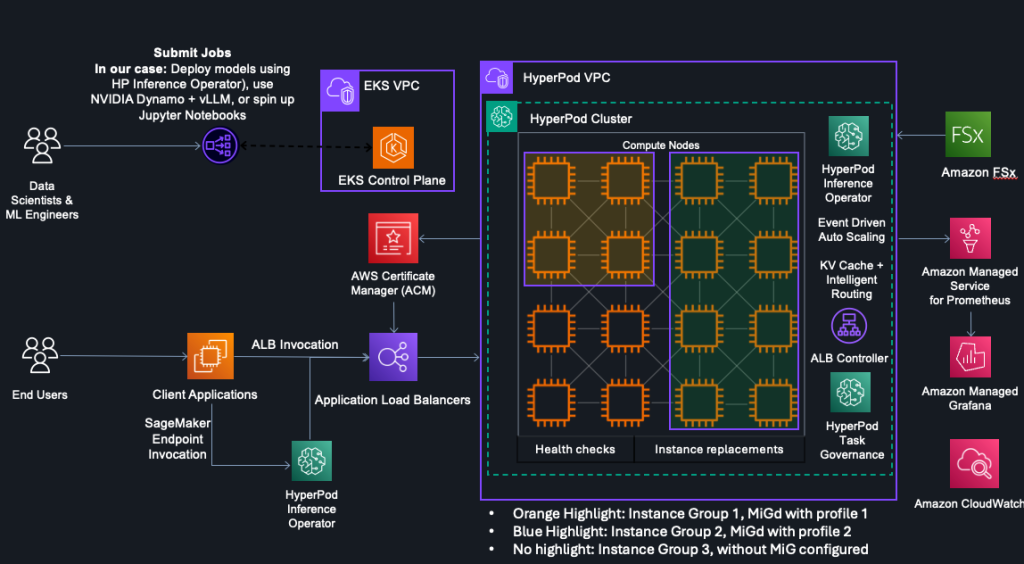
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

Power up your ML workflows with interactive IDEs on SageMaker HyperPod
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.

HyperPod enhances ML infrastructure with security and storage
This blog post introduces two major enhancements to Amazon SageMaker HyperPod that strengthen security and storage capabilities for large-scale machine learning infrastructure. The new features include customer managed key (CMK) support for encrypting EBS volumes with organization-controlled encryption keys, and Amazon EBS CSI driver integration that enables dynamic storage management for Kubernetes volumes in AI workloads.
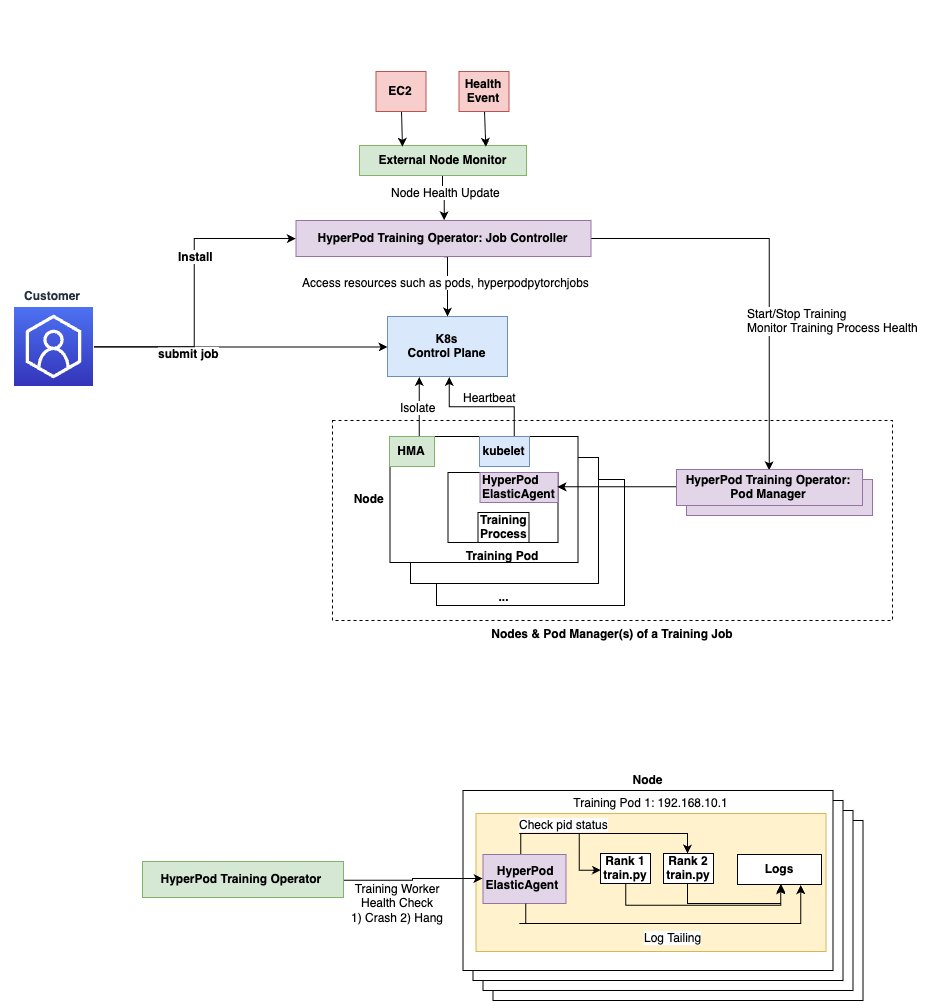
Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator
In this post, we demonstrate how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, which enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities. The Amazon SageMaker HyperPod training operator helps accelerate generative AI model development by efficiently managing distributed training across large GPU clusters, offering benefits like centralized training process monitoring, granular process recovery, and hanging job detection that can reduce recovery times from tens of minutes to seconds.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.
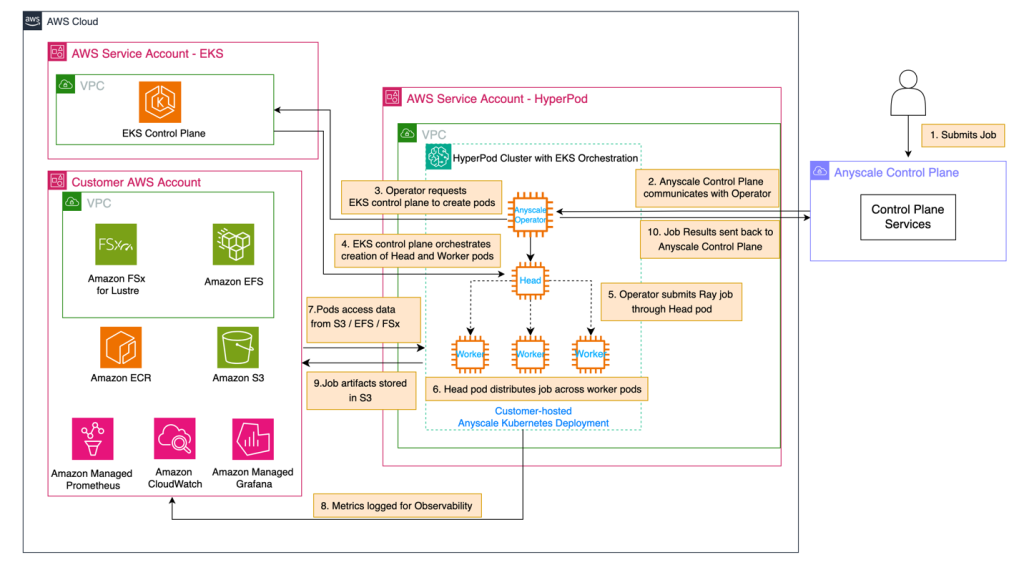
Use Amazon SageMaker HyperPod and Anyscale for next-generation distributed computing
In this post, we demonstrate how to integrate Amazon SageMaker HyperPod with Anyscale platform to address critical infrastructure challenges in building and deploying large-scale AI models. The combined solution provides robust infrastructure for distributed AI workloads with high-performance hardware, continuous monitoring, and seamless integration with Ray, the leading AI compute engine, enabling organizations to reduce time-to-market and lower total cost of ownership.
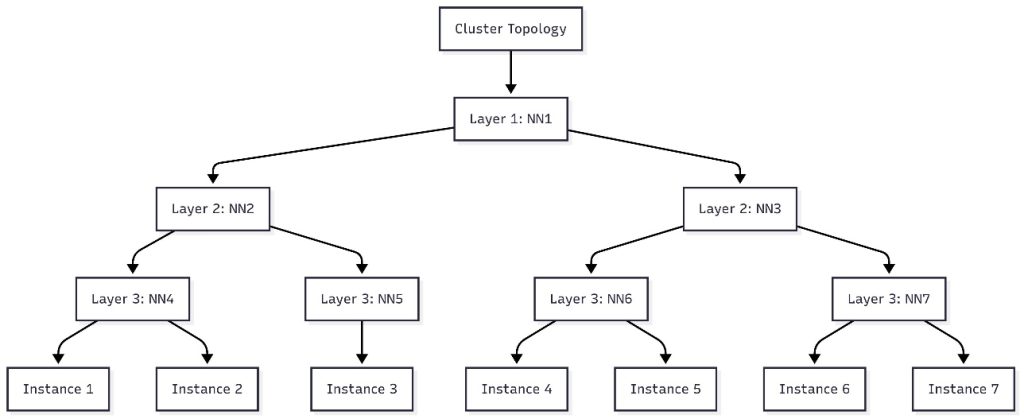
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.

Powering innovation at scale: How AWS is tackling AI infrastructure challenges
As generative AI continues to transform how enterprises operate—and develop net new innovations—the infrastructure demands for training and deploying AI models have grown exponentially. Traditional infrastructure approaches are struggling to keep pace with today’s computational requirements, network demands, and resilience needs of modern AI workloads. At AWS, we’re also seeing a transformation across the technology […]

Accelerate your model training with managed tiered checkpointing on Amazon SageMaker HyperPod
AWS announced managed tiered checkpointing in Amazon SageMaker HyperPod, a purpose-built infrastructure to scale and accelerate generative AI model development across thousands of AI accelerators. Managed tiered checkpointing uses CPU memory for high-performance checkpoint storage with automatic data replication across adjacent compute nodes for enhanced reliability. In this post, we dive deep into those concepts and understand how to use the managed tiered checkpointing feature.