Artificial Intelligence
Category: Generative AI
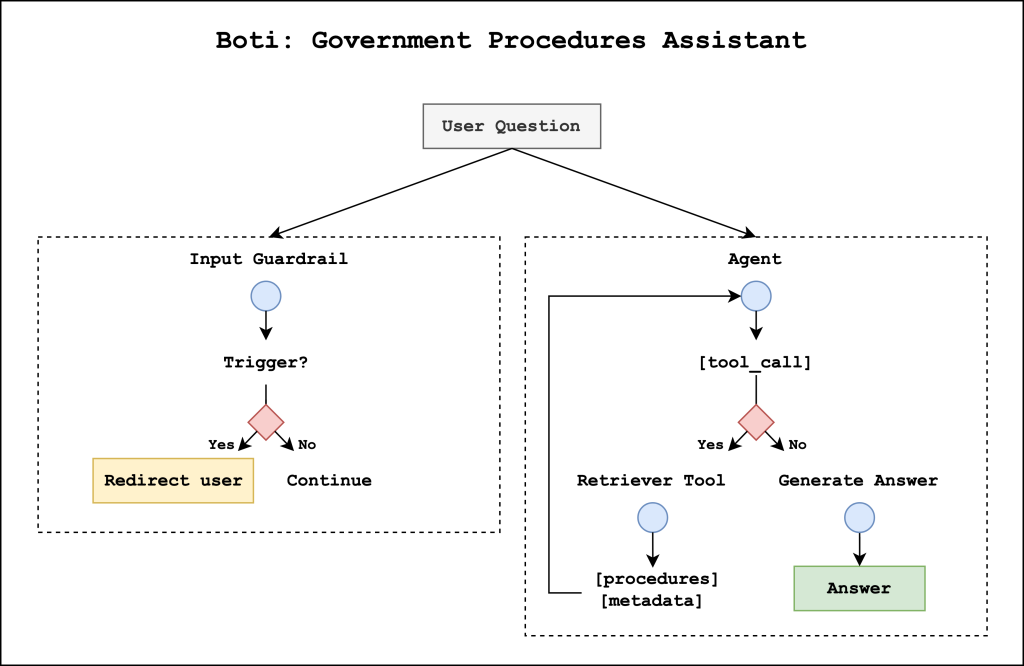
Meet Boti: The AI assistant transforming how the citizens of Buenos Aires access government information with Amazon Bedrock
This post describes the agentic AI assistant built by the Government of the City of Buenos Aires and the GenAIIC to respond to citizens’ questions about government procedures. The solution consists of two primary components: an input guardrail system that helps prevent the system from responding to harmful user queries and a government procedures agent that retrieves relevant information and generates responses.

Beyond the basics: A comprehensive foundation model selection framework for generative AI
As the model landscape expands, organizations face complex scenarios when selecting the right foundation model for their applications. In this blog post we present a systematic evaluation methodology for Amazon Bedrock users, combining theoretical frameworks with practical implementation strategies that empower data scientists and machine learning (ML) engineers to make optimal model selections.
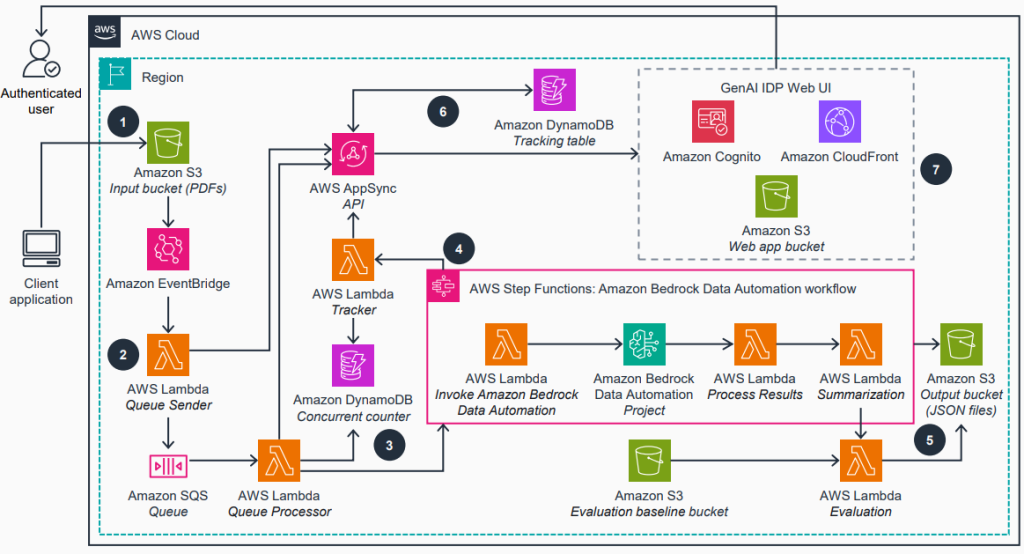
Accelerate intelligent document processing with generative AI on AWS
In this post, we introduce our open source GenAI IDP Accelerator—a tested solution that we use to help customers across industries address their document processing challenges. Automated document processing workflows accurately extract structured information from documents, reducing manual effort. We will show you how this ready-to-deploy solution can help you build those workflows with generative AI on AWS in days instead of months.

Fine-tune OpenAI GPT-OSS models using Amazon SageMaker HyperPod recipes
This post is the second part of the GPT-OSS series focusing on model customization with Amazon SageMaker AI. In Part 1, we demonstrated fine-tuning GPT-OSS models using open source Hugging Face libraries with SageMaker training jobs, which supports distributed multi-GPU and multi-node configurations, so you can spin up high-performance clusters on demand. In this post, […]

Create personalized products and marketing campaigns using Amazon Nova in Amazon Bedrock
Built using Amazon Nova in Amazon Bedrock, The Fragrance Lab represents a comprehensive end-to-end application that illustrates the transformative power of generative AI in retail, consumer goods, advertising, and marketing. In this post, we explore the development of The Fragrance Lab. Our vision was to craft a unique blend of physical and digital experiences that would celebrate creativity, advertising, and consumer goods while capturing the spirit of the French Riviera.
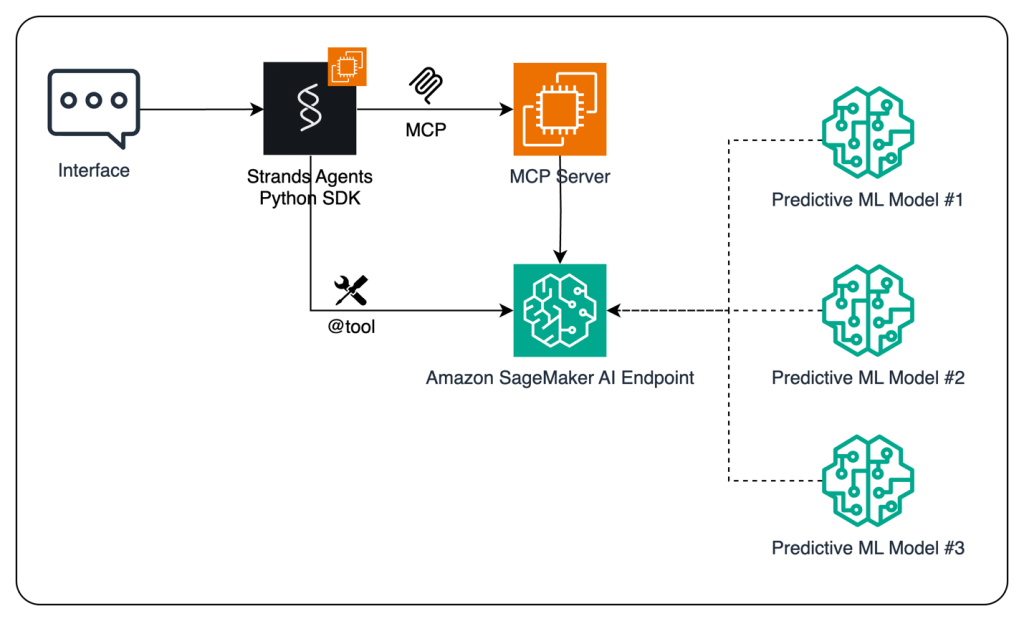
Enhance AI agents using predictive ML models with Amazon SageMaker AI and Model Context Protocol (MCP)
In this post, we demonstrate how to enhance AI agents’ capabilities by integrating predictive ML models using Amazon SageMaker AI and the MCP. By using the open source Strands Agents SDK and the flexible deployment options of SageMaker AI, developers can create sophisticated AI applications that combine conversational AI with powerful predictive analytics capabilities.
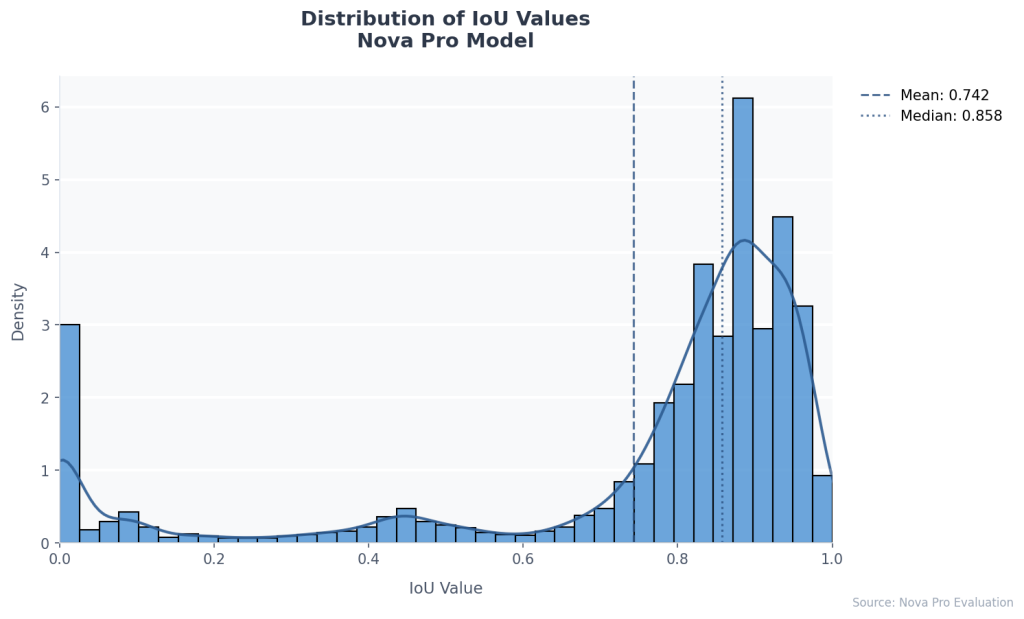
Benchmarking document information localization with Amazon Nova
This post demonstrates how to use foundation models (FMs) in Amazon Bedrock, specifically Amazon Nova Pro, to achieve high-accuracy document field localization while dramatically simplifying implementation. We show how these models can precisely locate and interpret document fields with minimal frontend effort, reducing processing errors and manual intervention.
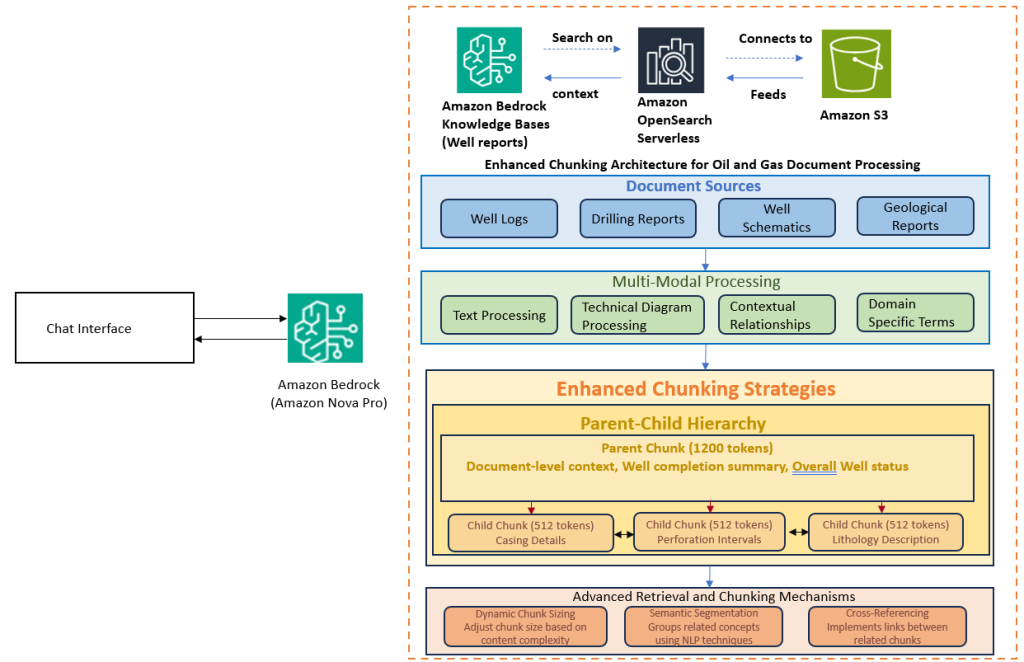
How Infosys built a generative AI solution to process oil and gas drilling data with Amazon Bedrock
We built an advanced RAG solution using Amazon Bedrock leveraging Infosys Topaz™ AI capabilities, tailored for the oil and gas sector. This solution excels in handling multimodal data sources, seamlessly processing text, diagrams, and numerical data while maintaining context and relationships between different data elements. In this post, we provide insights on the solution and walk you through different approaches and architecture patterns explored, like different chunking, multi-vector retrieval, and hybrid search during the development.
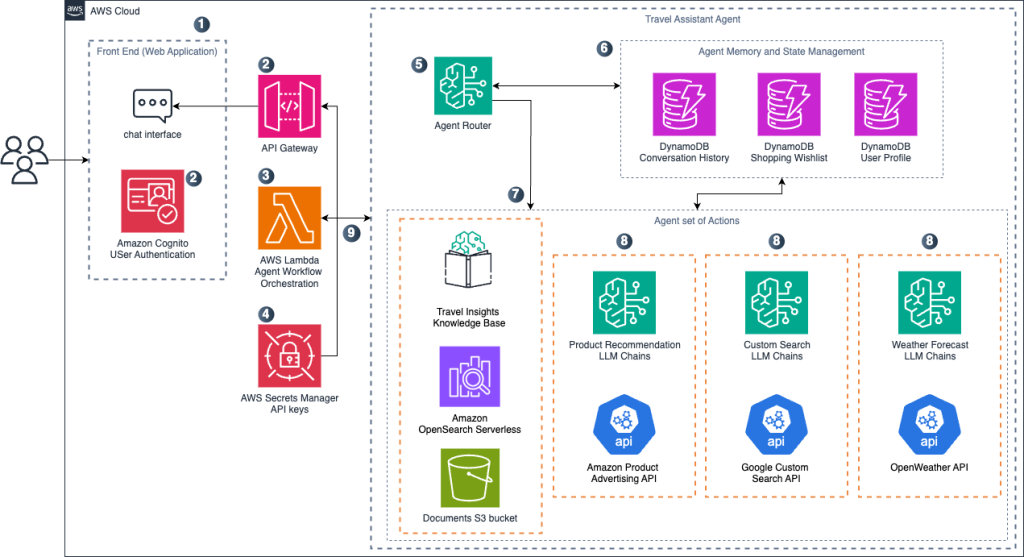
Create a travel planning agentic workflow with Amazon Nova
In this post, we explore how to build a travel planning solution using AI agents. The agent uses Amazon Nova, which offers an optimal balance of performance and cost compared to other commercial LLMs. By combining accurate but cost-efficient Amazon Nova models with LangGraph orchestration capabilities, we create a practical travel assistant that can handle complex planning tasks while keeping operational costs manageable for production deployments.
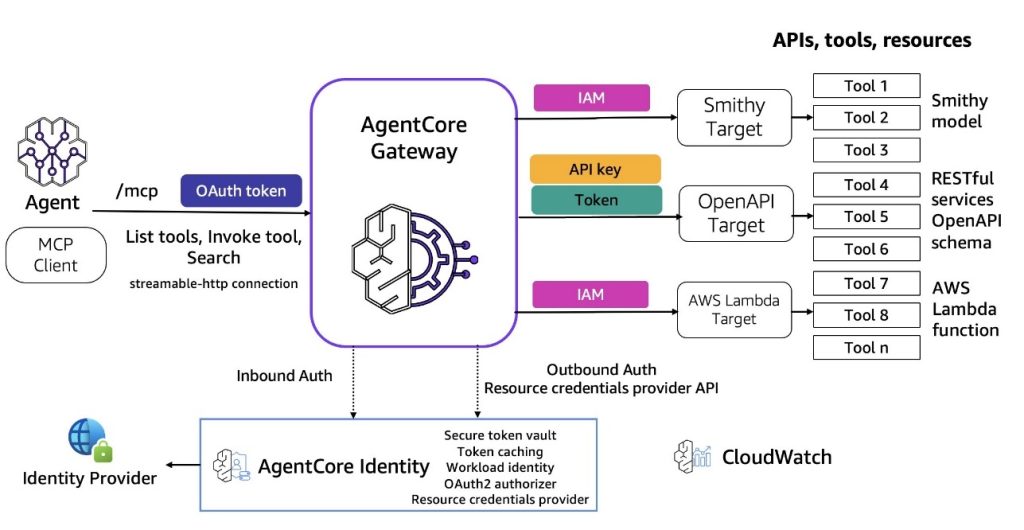
Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including Security Guard, Translation, Composition, Target extensibility, Infrastructure Manager, and Semantic Tool Selection, while implementing sophisticated dual-sided security architecture for both inbound and outbound connections.