Artificial Intelligence
Category: AWS Neuron
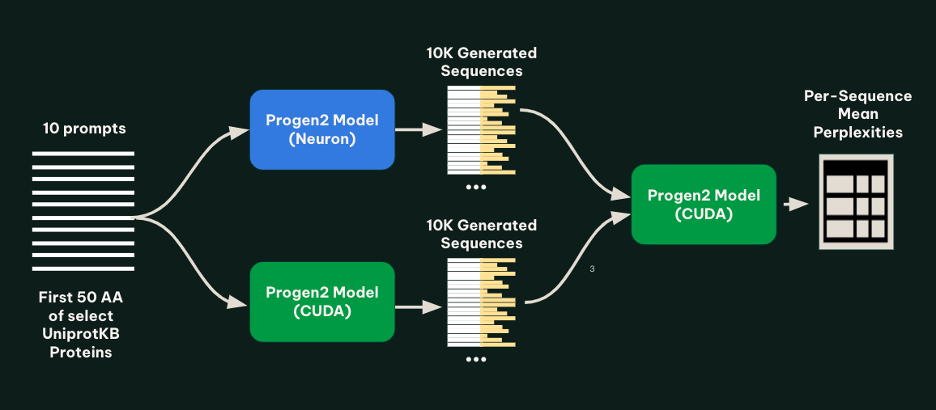
Metagenomi generates millions of novel enzymes cost-effectively using AWS Inferentia
In this post, we detail how Metagenomi partnered with AWS to implement the Progen2 protein language model on AWS Inferentia, achieving up to 56% cost reduction for high-throughput enzyme generation workflows. The implementation enabled cost-effective generation of millions of novel enzyme variants using EC2 Inf2 Spot Instances and AWS Batch, demonstrating how cloud-based generative AI can make large-scale protein design more accessible for biotechnology applications .

Cost-effective AI image generation with PixArt-Sigma inference on AWS Trainium and AWS Inferentia
This post is the first in a series where we will run multiple diffusion transformers on Trainium and Inferentia-powered instances. In this post, we show how you can deploy PixArt-Sigma to Trainium and Inferentia-powered instances.

Optimizing Mixtral 8x7B on Amazon SageMaker with AWS Inferentia2
This post demonstrates how to deploy and serve the Mixtral 8x7B language model on AWS Inferentia2 instances for cost-effective, high-performance inference. We’ll walk through model compilation using Hugging Face Optimum Neuron, which provides a set of tools enabling straightforward model loading, training, and inference, and the Text Generation Inference (TGI) Container, which has the toolkit for deploying and serving LLMs with Hugging Face.

How to run Qwen 2.5 on AWS AI chips using Hugging Face libraries
In this post, we outline how to get started with deploying the Qwen 2.5 family of models on an Inferentia instance using Amazon Elastic Compute Cloud (Amazon EC2) and Amazon SageMaker using the Hugging Face Text Generation Inference (TGI) container and the Hugging Face Optimum Neuron library. Qwen2.5 Coder and Math variants are also supported.

Deploy Meta Llama 3.1-8B on AWS Inferentia using Amazon EKS and vLLM
In this post, we walk through the steps to deploy the Meta Llama 3.1-8B model on Inferentia 2 instances using Amazon EKS. This solution combines the exceptional performance and cost-effectiveness of Inferentia 2 chips with the robust and flexible landscape of Amazon EKS. Inferentia 2 chips deliver high throughput and low latency inference, ideal for LLMs.

Serving LLMs using vLLM and Amazon EC2 instances with AWS AI chips
The use of large language models (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance […]

Deploy Meta Llama 3.1 models cost-effectively in Amazon SageMaker JumpStart with AWS Inferentia and AWS Trainium
We’re excited to announce the availability of Meta Llama 3.1 8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 by up to 50%. In this post, we demonstrate how to deploy Meta Llama 3.1 on Trainium and Inferentia instances in SageMaker JumpStart.

Node problem detection and recovery for AWS Neuron nodes within Amazon EKS clusters
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). This component can quickly detect rare occurrences of issues when Neuron devices fail by tailing monitoring logs. It marks the worker nodes in a defective Neuron device as unhealthy, and promptly replaces them with new worker nodes. By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure.

Scale and simplify ML workload monitoring on Amazon EKS with AWS Neuron Monitor container
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container, an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to […]

Accelerate deep learning training and simplify orchestration with AWS Trainium and AWS Batch
In large language model (LLM) training, effective orchestration and compute resource management poses a significant challenge. Automation of resource provisioning, scaling, and workflow management is vital for optimizing resource usage and streamlining complex workflows, thereby achieving efficient deep learning training processes. Simplified orchestration enables researchers and practitioners to focus more on model experimentation, hyperparameter tuning, […]