Artificial Intelligence
Category: AWS Inferentia
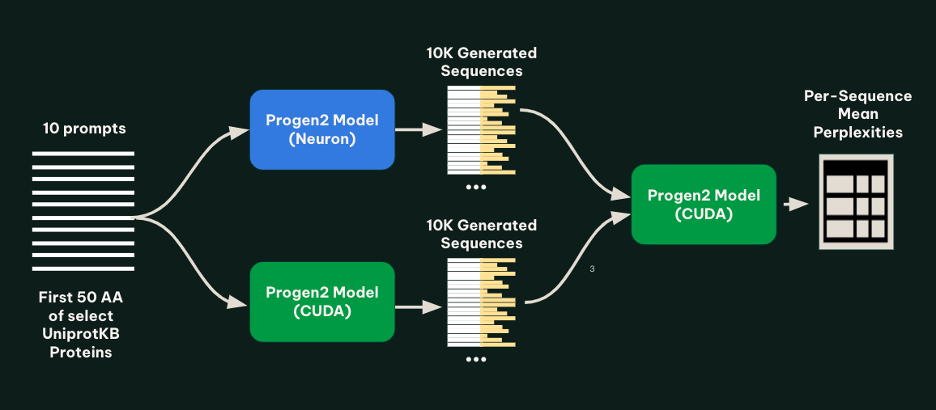
Metagenomi generates millions of novel enzymes cost-effectively using AWS Inferentia
In this post, we detail how Metagenomi partnered with AWS to implement the Progen2 protein language model on AWS Inferentia, achieving up to 56% cost reduction for high-throughput enzyme generation workflows. The implementation enabled cost-effective generation of millions of novel enzyme variants using EC2 Inf2 Spot Instances and AWS Batch, demonstrating how cloud-based generative AI can make large-scale protein design more accessible for biotechnology applications .

Enabling customers to deliver production-ready AI agents at scale
Today, I’m excited to share how we’re bringing this vision to life with new capabilities that address the fundamental aspects of building and deploying agents at scale. These innovations will help you move beyond experiments to production-ready agent systems that can be trusted with your most critical business processes.

How Rufus doubled their inference speed and handled Prime Day traffic with AWS AI chips and parallel decoding
Rufus, an AI-powered shopping assistant, relies on many components to deliver its customer experience including a foundation LLM (for response generation) and a query planner (QP) model for query classification and retrieval enhancement. This post focuses on how the QP model used draft centric speculative decoding (SD)—also called parallel decoding—with AWS AI chips to meet the demands of Prime Day. By combining parallel decoding with AWS Trainium and Inferentia chips, Rufus achieved two times faster response times, a 50% reduction in inference costs, and seamless scalability during peak traffic.

Cost-effective AI image generation with PixArt-Sigma inference on AWS Trainium and AWS Inferentia
This post is the first in a series where we will run multiple diffusion transformers on Trainium and Inferentia-powered instances. In this post, we show how you can deploy PixArt-Sigma to Trainium and Inferentia-powered instances.

Optimizing Mixtral 8x7B on Amazon SageMaker with AWS Inferentia2
This post demonstrates how to deploy and serve the Mixtral 8x7B language model on AWS Inferentia2 instances for cost-effective, high-performance inference. We’ll walk through model compilation using Hugging Face Optimum Neuron, which provides a set of tools enabling straightforward model loading, training, and inference, and the Text Generation Inference (TGI) Container, which has the toolkit for deploying and serving LLMs with Hugging Face.

How to run Qwen 2.5 on AWS AI chips using Hugging Face libraries
In this post, we outline how to get started with deploying the Qwen 2.5 family of models on an Inferentia instance using Amazon Elastic Compute Cloud (Amazon EC2) and Amazon SageMaker using the Hugging Face Text Generation Inference (TGI) container and the Hugging Face Optimum Neuron library. Qwen2.5 Coder and Math variants are also supported.

ByteDance processes billions of daily videos using their multimodal video understanding models on AWS Inferentia2
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day. In this post, we discuss the use of multimodal LLMs for video understanding, the solution architecture, and techniques for performance optimization.

Fine-tune and host SDXL models cost-effectively with AWS Inferentia2
As technology continues to evolve, newer models are emerging, offering higher quality, increased flexibility, and faster image generation capabilities. One such groundbreaking model is Stable Diffusion XL (SDXL), released by StabilityAI, advancing the text-to-image generative AI technology to unprecedented heights. In this post, we demonstrate how to efficiently fine-tune the SDXL model using SageMaker Studio. We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances, unlocking superior price performance for your inference workloads.

Deploy Meta Llama 3.1-8B on AWS Inferentia using Amazon EKS and vLLM
In this post, we walk through the steps to deploy the Meta Llama 3.1-8B model on Inferentia 2 instances using Amazon EKS. This solution combines the exceptional performance and cost-effectiveness of Inferentia 2 chips with the robust and flexible landscape of Amazon EKS. Inferentia 2 chips deliver high throughput and low latency inference, ideal for LLMs.

Serving LLMs using vLLM and Amazon EC2 instances with AWS AI chips
The use of large language models (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance […]