Artificial Intelligence
Category: Amazon Textract
Oldcastle accelerates document processing with Amazon Bedrock
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort.
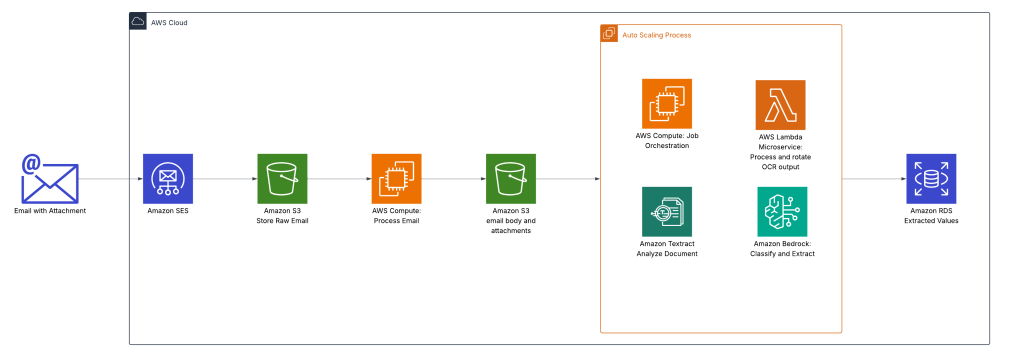
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

How Gardenia Technologies helps customers create ESG disclosure reports 75% faster using agentic generative AI on Amazon Bedrock
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI, a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. This post dives deep into the technology behind an agentic search solution using tooling with Retrieval Augmented Generation (RAG) and text-to-SQL capabilities to help customers reduce ESG reporting time by up to 75%. We demonstrate how AWS serverless technology, combined with agents in Amazon Bedrock, are used to build scalable and highly flexible agent-based document assistant applications.

How E.ON plans to significantly reduce Metering costs annually with AI diagnostics for smart meters powered by Amazon Textract
E.ON’s story highlights how a creative application of Amazon Textract, combined with custom image analysis and pulse counting, can solve a real-world challenge at scale. By diagnosing smart meter errors through brief smartphone videos, E.ON aims to lower costs, improve customer satisfaction, and enhance overall energy service reliability. In this post, we dive into how this solution works and the impact it’s making.

Automating complex document processing: How Onity Group built an intelligent solution using Amazon Bedrock
In this post, we explore how Onity Group, a financial services company specializing in mortgage servicing and origination, transformed their document processing capabilities using Amazon Bedrock and other AWS services. The solution helped Onity achieve a 50% reduction in document extraction costs while improving overall accuracy by 20% compared to their previous OCR and AI/ML solution.

Unleashing the multimodal power of Amazon Bedrock Data Automation to transform unstructured data into actionable insights
Today, we’re excited to announce the general availability of Amazon Bedrock Data Automation, a powerful, fully managed capability within Amazon Bedrock that seamlessly transforms unstructured multimodal data into structured, application-ready insights with high accuracy, cost efficiency, and scalability.

How Pattern PXM’s Content Brief is driving conversion on ecommerce marketplaces using AI
Pattern is a leader in ecommerce acceleration, helping brands navigate the complexities of selling on marketplaces and achieve profitable growth through a combination of proprietary technology and on-demand expertise. In this post, we share how Pattern uses AWS services to process trillions of data points to deliver actionable insights, optimizing product listings across multiple services.

How Travelers Insurance classified emails with Amazon Bedrock and prompt engineering
In this post, we discuss how FMs can reliably automate the classification of insurance service emails through prompt engineering. When formulating the problem as a classification task, an FM can perform well enough for production environments, while maintaining extensibility into other tasks and getting up and running quickly. All experiments were conducted using Anthropic’s Claude models on Amazon Bedrock.

How Crexi achieved ML models deployment on AWS at scale and boosted efficiency
Commercial Real Estate Exchange, Inc. (Crexi), is a digital marketplace and platform designed to streamline commercial real estate transactions. In this post, we will review how Crexi achieved its business needs and developed a versatile and powerful framework for AI/ML pipeline creation and deployment. This customizable and scalable solution allows its ML models to be efficiently deployed and managed to meet diverse project requirements.

Multilingual content processing using Amazon Bedrock and Amazon A2I
This post outlines a custom multilingual document extraction and content assessment framework using a combination of Anthropic’s Claude 3 on Amazon Bedrock and Amazon A2I to incorporate human-in-the-loop capabilities.