Artificial Intelligence
Build a serverless anomaly detection tool using Java and the Amazon SageMaker Random Cut Forest algorithm
One of the problems that business owners commonly face is detecting when something unusual is happening in their business. Detecting unusual user activity or changes in daily traffic patterns are just some of the challenges. With an ever-increasing amount of data and metrics, detecting anomalies with the help of machine learning is a great way to proactively identify problems.
In this blog post we’ll explain how to build a serverless anomaly detection tool using Amazon SageMaker with Java. Amazon SageMaker makes it easy to train and host machine learning models, and the available built-in algorithms solve common business problems. To solve this particular business problem, we’ll use the Random Cut Forest (RCF) anomaly detection algorithm. Amazon Web Services offers a broad set of global cloud-based products to help organizations move faster, lower IT costs, and scale. We’ll demonstrate how these can be used to build a serverless anomaly detection tool. While Python is one of the most popular programming languages for tackling machine learning problems, many users build micro-services and serverless applications using Java and other JVM-based languages. By the end of this blog post you’ll be able to enable machine learning in your Java applications using Amazon SageMaker.
Throughout the blog post we will use Java code snippets to focus on particular aspects of the tool. You can find the code used to build and deploy this solution into your own AWS account here.
Problem overview
In our example, Alice is a Java developer who owns a video streaming platform that runs on top of multiple AWS services and serves thousands of customers. Alice sets up dashboards to track metrics that show how well her platform is performing. One of the most important metrics she looks at is the total number of active users of the platform, as shown in the following diagram.
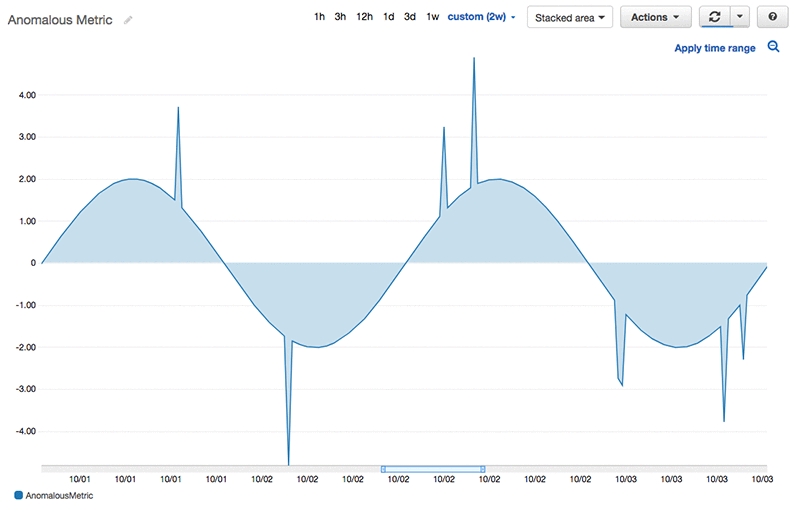
This metric shows a general daily pattern of usage, but it also changes seasonally. A low number of active users, a high number of active users, and breaks of daily pattern are all considered anomalies. Alice is mostly interested in understanding the root cause for those anomalous datapoints. Currently, she doesn’t rely on automated tools for finding anomalies in the data. Instead, she goes through a manual process and spend a lot of time identifying spikes, dips, and breaks in periodicity. Fixed thresholds or threshold windows don’t work for her due to changing patterns and seasonality. She needs a better solution!
What can we do to make Alice’s life easier?
Solution architecture
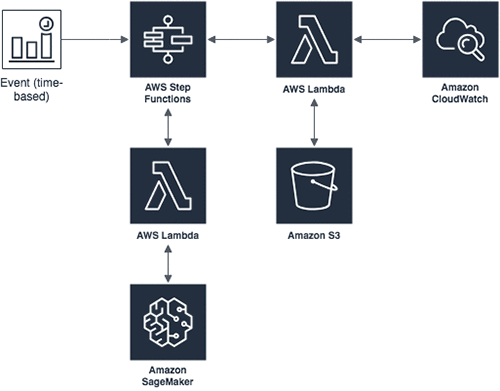
To help Alice solve her anomaly detection problem we first need to identify all the building blocks for an anomaly detection tool:
- Amazon SageMaker– We’ll need Amazon SageMaker to easily build a model based on the historical metric data. Then, we’ll use it to find anomalous data points in current data (from the previous week). The Amazon SageMaker Random Cut Forest algorithm learns the trends in your data and after training can identify anomalies. For using your trained model to find anomalies, we can choose between two options: (1) We can host a model on an endpoint and run inference requests against that endpoint using HTTP requests. (2) We can use a batch transform job to bulk transform new metric data. We need to get results once a week, so the batch transform job seems like a better option. Hosting a model and then hitting an endpoint once a week would be a waste of resources.
- Amazon CloudWatch Events – We’ll use Amazon CloudWatch Events to schedule a recurring weekly event that triggers our weekly transformation job. The patterns in the underlying data will change over time, so it’s important to occasionally refresh the model we’re using. We will use another CloudWatch Events rule to run a training job once per month.
- Amazon CloudWatch Metrics– Alice stores all of her metrics in CloudWatch, which we’ll use as our data source. We’ll also publish our anomalous metric scores to CloudWatch from the batch transform job so Alice can easily view when anomalies occur.
- Amazon S3 –Amazon SageMaker uses Amazon S3 as an input data source for training and batch transform jobs. After we retrieve and preprocess CloudWatch data we will store it in S3 for our Amazon SageMaker jobs.
- AWS Step Functions– Getting data from CloudWatch, uploading it to S3, starting the training and batch transform jobs, and publishing the results back to CloudWatch are all steps that we need so that our anomaly detection tool works as expected. Instead of writing a new service to orchestrate this workflow, we’ll use serverless technologies to simplify the process, and we’ll automate the process using AWS Step Functions. We’ll use two state machines, one for training and one for batch inference, which will ensure that all of the described steps are being executed in the correct order and that any failures are handled gracefully.
- AWS Lambda– All the previously described actions will be executed as AWS Lambda functions, which will be triggered by the AWS Step Functions state machine. All of our Lambda functions use Java 8 and the AWS SDK. Note: Some of the Lambda functions could potentially be replaced following recent release of Amazon SageMaker support for Amazon States Language. However, in this blog post we want to focus on the perspective of Java development to provide unified view on the subject.
The following diagram illustrates our architecture:
Training job state machine
The following diagram illustrates the training state machine:

- The first Lambda function (“Store CloudWatch Metric Data in S3”) gets one-month worth of metric data from CloudWatch with a resolution of 5 minutes. The Lambda function creates a CSV file containing the timestamp and a value for each of the 5-minute data points, and uploads the file to the S3 bucket.
- The second Lambda function (“Start SageMaker Training Job”) uses the S3 dataset created in the previous step to start an Amazon SageMaker training job. The creation of the job is executed in asynchronous fashion and the execution of the state machine continues.
- Wait until the Amazon SageMaker training job is finished. If the job failed, we report the job failure and finish the execution. If the job has completed successfully we move to the next state.
- The final Lambda function (“Create SageMaker Model”) creates an Amazon SageMaker model based on model output created in training job.
Transform job state machine
The following diagram illustrates the transform job state machine:
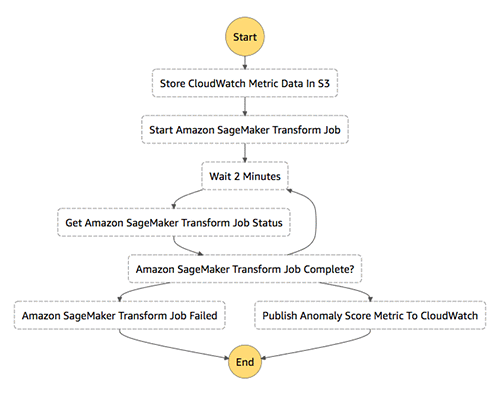
The following steps are executed as part of transform job state machine:
- We reuse same Lambda function as in the training step (“Store CloudWatch Metric Data in S3”), but we configure it to get only one week of data from CloudWatch.
- The second Lambda function (“Start SageMaker Transform Job”) finds the models we have trained (created by training state machine), picks the latest one, and asynchronously starts the Amazon SageMaker batch transform job.
- Wait until the batch transform job finishes successfully.
- The final Lambda function (“Publish Anomaly Score Metric to CloudWatch”) gets output scores from the batch transform job. It uses a simple, standard technique for classifying anomalies in which all anomaly scores outside three standard deviations from the mean score are considered anomalous. Finally, all the data points that have been labeled as anomalous are published to CloudWatch with a value of 1, and all the data points that haven’t been marked as anomalous are published with a value of 0. To know for which timestamp to publish the anomalous score metric, we use the input dataset.
After both state machines have run, a new metric is available in the Amazon CloudWatch console. We can graph this new metric over the original metric to understand when anomalies happen. Now Alice can use the new metric to zoom in on specific points of interest in her original metric, and navigate to the Amazon CloudWatch Logs console for those data points.
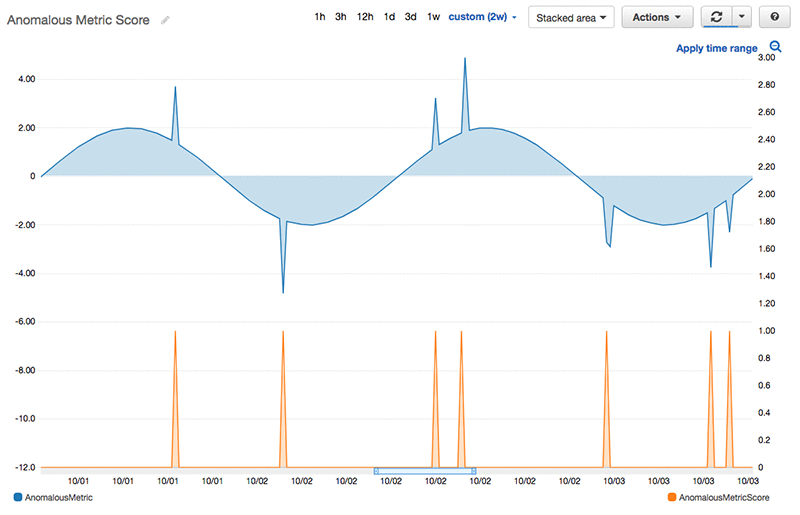
Since Alice is storing anomalies in CloudWatch, she can use all of the rich alerting and monitoring functionality that is available so she can be notified automatically when something strange happens. Similarly, because she is using Amazon SageMaker s she can take the model and use it for online inference in the future if she wants to (for example, she can evaluate anomalies in near real time by making HTTP calls to a hosted endpoint).
Conclusion
In this blog post we showed you how to build an automated anomaly detection tool using Amazon SageMaker. We explained what services help us remove the undifferentiated heavy lifting to build the tool and how they all fit together to form a meaningful workflow. We also showcased one of the latest Amazon SageMaker releases, batch transform jobs, which is ideal for use cases that don’t require hosting a model for near real-time inference. All the Lambda functions were written using Java 8. It is our hope that this blog post, in combination with code examples, will help Java developers integrate Amazon SageMaker into their services and applications.
About the authors
 Luka Krajcar is a Software Development Engineer on the AWS AI Labs team. He received his M.S. in Computer Science at the Faculty of Electrical Engineering and Computing at the University of Zagreb. Outside of work, Luka enjoys reading fiction, running, and video gaming.
Luka Krajcar is a Software Development Engineer on the AWS AI Labs team. He received his M.S. in Computer Science at the Faculty of Electrical Engineering and Computing at the University of Zagreb. Outside of work, Luka enjoys reading fiction, running, and video gaming.
 Julio Delgado Mangas is a Software Development Engineer on the AWS AI Labs team. He has contributed to AWS services like Amazon CloudWatch and the Amazon QuickSight SPICE engine. Before joining Amazon, he was a research engineer on the Human Brain Project.
Julio Delgado Mangas is a Software Development Engineer on the AWS AI Labs team. He has contributed to AWS services like Amazon CloudWatch and the Amazon QuickSight SPICE engine. Before joining Amazon, he was a research engineer on the Human Brain Project.
 Laurence Rouesnel is the Algorithms & Platforms Group Manager in Amazon AI Labs. He leads a team of engineers and scientists working on deep learning and machine learning research and products. In his spare time, he is an avid traveler, and loves the outdoors whether it’s hiking, skiing, or windsurfing.
Laurence Rouesnel is the Algorithms & Platforms Group Manager in Amazon AI Labs. He leads a team of engineers and scientists working on deep learning and machine learning research and products. In his spare time, he is an avid traveler, and loves the outdoors whether it’s hiking, skiing, or windsurfing.
 Chris Swierczewski is an Applied Scientist on the AWS AI Labs team, where he has contributed to the Amazon SageMaker Latent Dirichlet Allocation and the Amazon SageMaker Random Cut Forest algorithms. Before Amazon, Chris was a Ph.D. student in Applied Mathematics at the University of Washington. He likes to go hiking, backpacking, and camping with his wife and their dog, River.
Chris Swierczewski is an Applied Scientist on the AWS AI Labs team, where he has contributed to the Amazon SageMaker Latent Dirichlet Allocation and the Amazon SageMaker Random Cut Forest algorithms. Before Amazon, Chris was a Ph.D. student in Applied Mathematics at the University of Washington. He likes to go hiking, backpacking, and camping with his wife and their dog, River.
 Madhav Jha is an Applied Scientist on the AWS AI Labs team where he uses his background in sublinear algorithms to develop scalable machine learning algorithms. He is a theoretical computer scientist who enjoys coding. He is always up for coffee conversations on startups and technology.
Madhav Jha is an Applied Scientist on the AWS AI Labs team where he uses his background in sublinear algorithms to develop scalable machine learning algorithms. He is a theoretical computer scientist who enjoys coding. He is always up for coffee conversations on startups and technology.