The Internet of Things on AWS – Official Blog
Using Chainer Neural Network Framework with AWS Greengrass ML Inference
Starting today, Greengrass ML inference includes a pre-built Chainer package for all devices powered by Intel Atom, NVIDIA Jetson TX2, and Raspberry Pi. So, you don’t have to build and configure the ML framework for your devices from scratch. With this launch, we now provide pre-built packages for three popular machine learning frameworks including TensorFlow, Apache MXNet, and Chainer. This blog post shows how to use Chainer with AWS Greengrass ML.
As a deep learning framework, Chainer Neural Network has been added to Greengrass MLI for several reasons.
- Empowers data scientists to take advantage of flexibility, power, and efficiency.
- Fosters quick iterative experiments and uses a bi-directional computational approach (forward-backwards) to converge on the best performing model.
- Uses familiar Python-based programing concepts complemented with dynamic network construction scheme and popular open source matrix libraries.
Chainer works in a similar fashion as existing Greengrass ML frameworks in that it depends on a library on the Greengrass and a set of model files generated using Amazon SageMaker and/or stored directly in an Amazon S3 bucket. From Amazon SageMaker or Amazon S3 the ML models can be deployed to AWS Greengrass to be used as a local resource for ML inference.
Conceptually, AWS IoT Core functions as the managing plane for deploying ML inference to the edge. A typical IoT analytics and ML cycle is represented below.
- Data is generated by device sensors and sent to AWS Greengrass and then on to AWS IoT Core. Data is also consumed by ML models deployed to AWS Greengrass.
- An AWS IoT rule sends the data to a channel on AWS IoT Analytics and a cleansed, transformed, and enriched data set is generated using a pipeline.
- AWS IoT Analytics data sets are consumed by ML modeling with the goal to generate trained ML models that can be stored in Amazon S3 and Amazon SageMaker from where, in conjunction with Lambda functions, can be deployed to AWS Greengrass for ML inference. When deploying an ML model to AWS Greengrass please note that it can originate in an Amazon S3 bucket or Amazon SageMaker.

From AWS IoT Core, Software, then Machine Learning Libraries select Chainer, the platform you are using, and then Configure Download. Move/copy the entire .gz file to your Greengrass, uncompress, and run the install.

On the defined AWS Greengrass group you can add Chainer model files as a Machine Learning resource.
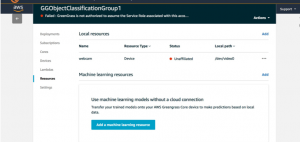
And then add a model from either Amazon SageMaker or from an Amazon S3 bucket.
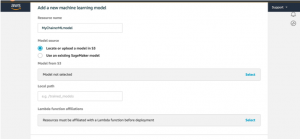
Multiple ML models can be added to a Greengrass group at the same time and for each one of them there must exist a corresponding Lambda function association.
From this point on, Chainer ML models can be consumed for AWS Greengrass ML inference by following existing documentation.
For step-by-step details on setting up AWS Greengrass ML Inference please consult the developer’s guide at https://docs.thinkwithwp.com/greengrass/latest/developerguide/ml-inference.html and https://docs.thinkwithwp.com/greengrass/latest/developerguide/ml-console.html.