AWS for Industries
Enabling efficient patient care using Amazon AI services
Artificial intelligence can speed up the development of new drug development, be a bridge to personalized medicine using the information of our genomes, and help address the problem of a chronic shortage of doctors (especially in countries where health services are underdeveloped). However, significant challenges remain before we can get there.
The challenge
The application of AI to the world’s health problems isn’t good enough yet. One of the main reasons is that the world’s health data is mostly in the form of large unstructured medical text, which makes the process costly, time-consuming, and inefficient. WHO estimates that < 20% of the world’s medical data is available in an ingestible format for AI algorithms to learn from and we’re just talking about developed countries.
In developing countries, the majority of patients visit the doctors through walk-ins instead of scheduled appointments. This leads to long wait times and chaotic waiting rooms. This adds to the stress and anxiety of the patients as well as the hospital staff. It also takes away the opportunity to collect data points and integrate them into the system to improve healthcare outcomes in the future.
This leads to one or more (but not limited to) of the following:
● Lack of continuity in patient-care
● Increased cost of care
● Poor patient experience
● Increased risk of disease contraction from the Out Patient Department (OPDs)
A potential solution
Luckily, technology and healthcare are having a moment. Healthcare institutions can leverage healthcare-specific AI solutions like Amazon Comprehend Medical and Amazon Transcribe to reduce costs, improve patient care and optimize the patient experience.
You can integrate these services and use them in conjunction with services like AWS Lambda, Amazon S3 , Amazon DynamoDB, and Amazon SQS to create a serverless healthcare solution, completely on top of AWS.
The solution architecture
This blog uses for following serverless reference architecture. It requires no software licenses to be procured and no management of virtual servers or operating systems. Billing of each of the services is pay-per-use, and you can plug-and-play over 210 AWS services within this stack based on your specific requirements.

Before we delve further, let’s understand what is going on in the architecture diagram.
- The patient records an audio clip describing her ailment on her smartphone that is uploaded to the S3 bucket.
- This triggers a Lambda function that initiates a transcription job converting the audio clip into a transcript.
- This job is monitored by CloudWatch, which triggers another Lambda function once the transcription job is completed.
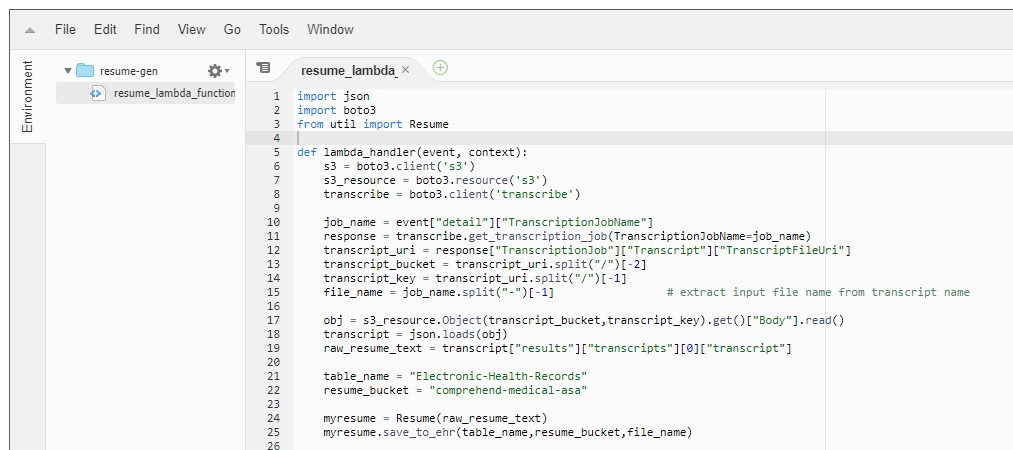
- The second Lambda function is in charge of passing the raw text of the transcript, obtained from the audio file, through Amazon Comprehend Medical (ACM).
- ACM helps extract medical entities, symptoms, dosage forms and their frequencies and presents them in an HTML format.
- These entities are then being stored in a DynamoDB table that can be then used for analytics by hospital management and stakeholders.
In summary, this serverless pipeline transforms and classifies your data. Once it is done, it presents the same to you in an HTML format. Let’s call it a Medical Resume for the purpose of this blog.
Deployment of the solution
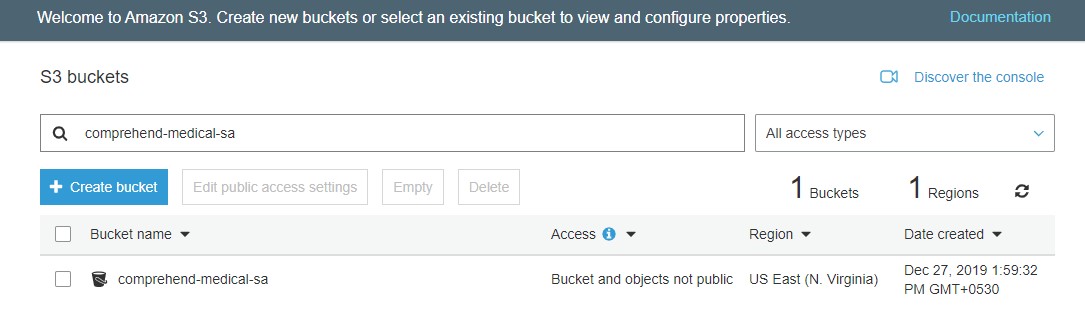
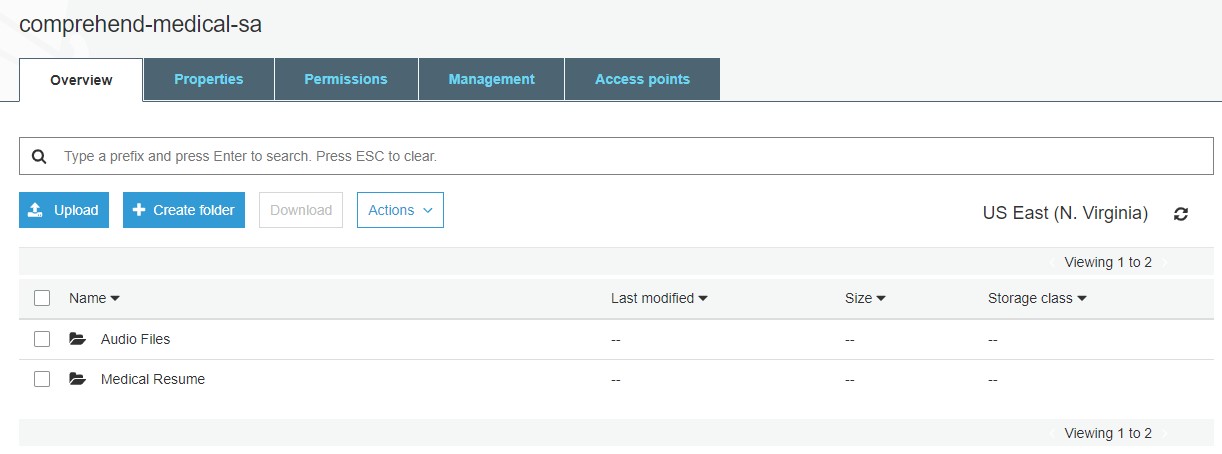
You must first create an Amazon S3 bucket with the name “comprehend-medical-sa” and two folders named “AudioFiles” and “MedicalResume”.
Now, you must create an Lambda function (say “transcription-job-function”) to initiate the transcription job. You also need to attach a role to it, giving it full access to Amazon S3 and Amazon Transcribe.
The details used for this post are against the corresponding fields –
- Function Name: transcription-job-function
- Runtime: Python 3.5
- Execution Role: Use an existing role
- Existing Role: “LambdaTranscribeRole”
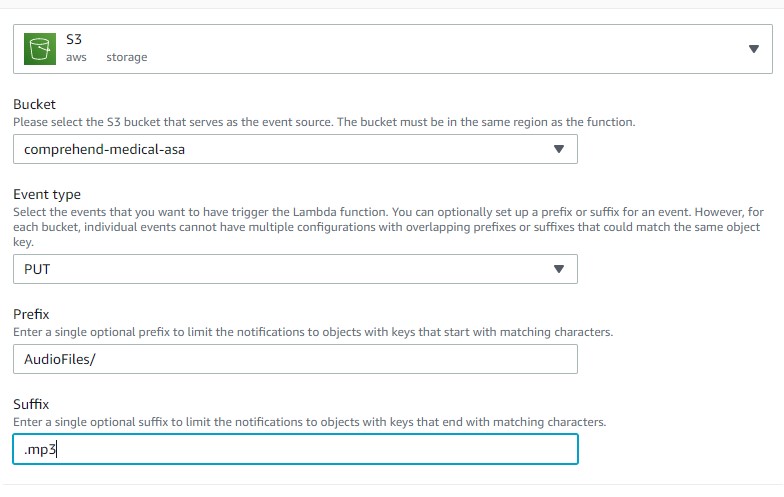
Add a “PUT” object role trigger on this Lambda function. This needs to be followed by the creation of a bucket, say “comprehend-medical-transcription-job”, which stores the output of the transcription job.
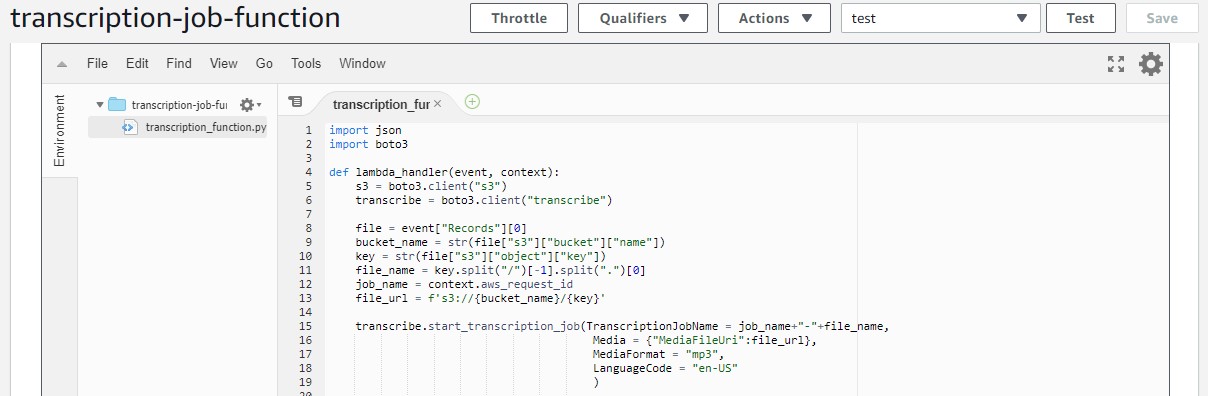
Once all the levers are in place, you can write the code to initiate the transcription job. The code for the “transcription-job-function” can be found directly here.
Now, create the other Lambda function, named “resume-gen”, which gets triggered through the CloudWatch event once the transcription job is completed. You again need to attach a role to it giving it access to Amazon S3, Amazon Transcribe, Amazon DynamoDB, and Amazon Comprehend Medical.
For initiating the trigger, navigate to CloudWatch and create an event rule named something like “transcribe-event”.
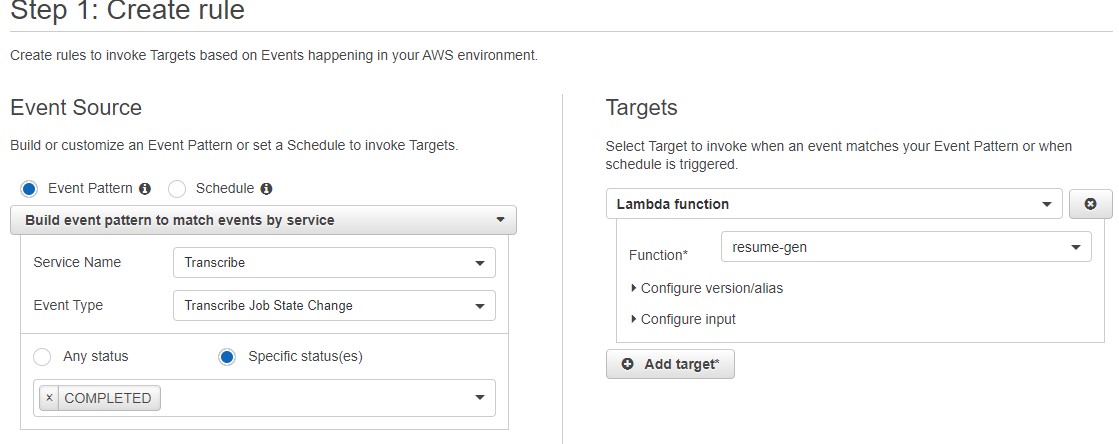
Triggering the second Lambda function (named “resume-gen”) can be tricky. To trigger it, you must stick to the following pipeline: “Add Trigger” → “CloudWatch Event” → “Transcribe Event”. (Transcribe Event is the name of the CloudWatch event rule you created in the previous step.)
You must make some other minor adjustments to “resume-gen” as you will use “pypandoc” and “ntlk” to generate the HTML file of the Medical Resume. You also need to add a layer of these packages to the “resume-gen” Lambda function. This is done by first creating a utility module, named “util.py”, adding it as a layer to create the Medical Resume and then save the medical record to the table.
The code for “util.py” can be downloaded from this GitHub repository. You can directly copy the code and paste it.
Now we’ll need to launch an EC2 instance, install the necessary dependencies, zip them into a package (say, “package.zip”), and then upload them to an Amazon S3 bucket (say, “lambda-layer-deployment-packages”).
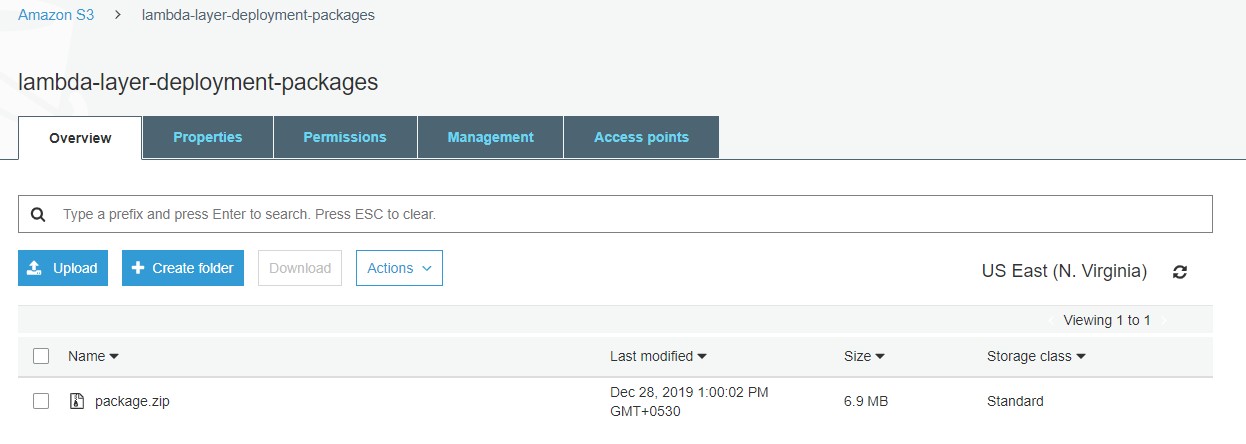
Navigate to the Lambda Console and create a layer (say, “pypandoc-nltk”). You also need to make a directory named Python containing the module “util.py” and zip this directory. You can choose to add the “Python 3.6” as the compatible runtime.
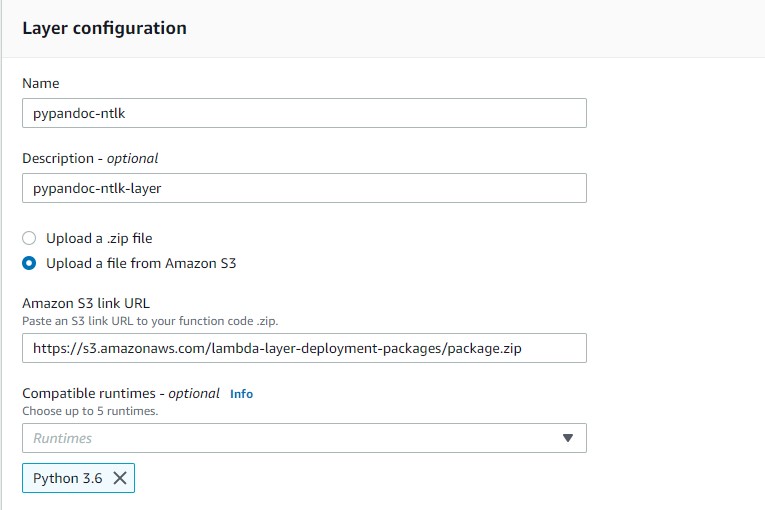
Now create a new layer (say, “util-layer”) and add these two layers (“pypandoc-nltk” and “util-layer”) to the Lambda Function.
 Finally, you need to write the code for the Lambda Function. This code can be found here.
Finally, you need to write the code for the Lambda Function. This code can be found here.
You can also create an Amazon DynamoDB table (with Table Name, say “Electronic-Health-Records”), to store the patient health records.
Conclusion
Using a serverless architecture to accurately create a Medical Resume/Medical Profile from the audio clips of medical consultations alleviates numerous clinical documentation-related challenges. An extended use case can also be found in telemedicine. People with minimal access to medical personnel can record their symptoms in an audio clip, which then gets transcribed and sent to the doctor in the form of a medical resume. This enables the doctor to offer medical advice to a larger audience, amplifying his presence virtually.
A similar use case can be implemented in Public Hospitals of developing countries where the wait times in the Out Patient Department (OPD) queues are high. In such a situation, patients can record an audio clip of their symptoms/history of their present medical condition. The process follows the above pipeline and generate a medical resume of the patient that helps the doctor cut through the chaff, prioritize and focus on objectives quicker.
There are several more possibilities, and we are excited to see how you extend this solution for your use cases. Please go ahead and give this a try. Comment below to tell us your experience!
If you want to learn more about this solution or other AWS Healthcare offerings, please visit https://thinkwithwp.com/health or contact your local AWS sales representative.
Stay well.