AWS Database Blog
Scale applications using multi-Region Amazon EKS and Amazon Aurora Global Database: Part 1
AWS offers a breadth and depth of services that helps you run and scale your critical workloads in multiple Regions on AWS’ global footprint. Whether you need a multi-Region architecture to support disaster recovery or bring your applications and the backend database into close proximity to your customers to reduce latency, AWS gives you the building blocks to improve your application availability, reliability, and latency. In this two-part series, we show you how you can use Amazon Elastic Kubernetes Service (Amazon EKS) to run your applications in multiple Regions. We use Amazon Aurora Global Database spanning multiple Regions as the persistent transaction data store, and AWS Global Accelerator to distribute traffic between Regions.
The Kubernetes declarative system makes it an ideal platform to orchestrate and operate containerized applications. In a declarative system, you declare the desired state, and the system observes the current and desired state and determines the actions required to reach the desired state from the current state. The Kubernetes declarative system makes it easier for you to set up applications and let Kubernetes manage the system state. It provides extended deployment and scaling capabilities, and automatically manages containerized applications. The Amazon EKS cluster provisioned per Region helps you to deploy and manage your containerized applications across Regions for High Availability (HA), Disaster Recovery (DR) and reduced latency. Visit Operating a multi-Region stateless applications using Amazon EKS to learn more.
Multi-Region transactional applications often rely on cross-Region low-latency, relational databases. Cross-Region failover for typical relational databases often requires a clear strategy, resources, and manual actions related to application reconfiguration. Managing such complex tasks can be challenging to the overall disaster recovery solution.
Aurora Global Database is designed for globally distributed applications, allowing a single Amazon Aurora database to span multiple Regions. It replicates your data with no impact on database performance, enables fast local reads with low latency in each Region, and provides disaster recovery from Region-wide outages.
In this post, you learn the architecture patterns and design attributes of a multi-Region application.
In our next post, we implement a solution for a retail website using microservices run on Amazon EKS clusters in multiple Regions, and Aurora Global Database (PostgreSQL-compatible edition) for transactional data persistence and low-latency local reads. We also look into how these microservices scale as demand increases, and how they transparently and automatically handle planned cross-Region Aurora Global Database failover.
Design patterns
In this section, we provide an overview of two different design patterns:
- Read local, write global – With this design pattern, users and applications in each Region perform the reads in their respective Regions. These applications are tolerant to eventual consistency. However, this design contains only one writer and applications running on both Regions send writes to this writer node.
- Read local, write local – With this design pattern, users and applications in each Region perform reads and writes locally in their respective Regions. The databases in this pattern replicate changes in both directions.
In this post, we focus on implementing our solution using the read local, write global design pattern.
Multi-Region application design
In this section, we discuss various design attributes of a multi-Region application.
High availability
Service and application continuity from transient failures and disaster recovery is one of the key reasons why enterprises look for multi-Region deployments.
Amazon EKS automatically detects and replaces unhealthy control plane instances. The Kubernetes declarative DevOps paradigm dynamically takes corrective actions for your applications based on the resource’s desired state defined in the manifest vs. its current state. This makes your application resilient to component-level failures naturally.
Aurora is designed to offer 99.99% availability, replicating six copies of your data within a Region and backing up your data continuously to Amazon Simple Storage Service (Amazon S3). It transparently recovers from physical storage failures; intra-Region instance failover typically takes less than 30 seconds.
Amazon Aurora Global Database supports cross-Region disaster recovery (DR) scenarios by using asynchronous storage replication between Regions. This enables very low replication latency minimizing both the potential for data loss as well as the time required to failover database to a new primary Region. These are referred as Recovery Point Objective (RPO), which is the amount of data loss that a business can tolerate and Recovery Time Objective (RTO), which is the time it takes for the system to begin taking normal requests from applications again. To learn more about Aurora Global Database refer to Using Amazon Aurora global databases.
Cross-Region failover to one of the secondaries in Aurora Global Database typically takes less than one minute. With an Aurora global database, you can choose from two different approaches to failover:
- Managed planned failover – With managed planned failover, you can failover to a secondary AWS Region while maintaining the replication topology and without having to recreate any secondary clusters. The RPO is 0 (no data loss) as it synchronizes secondary DB clusters with the primary before making any other changes. The duration (RTO) of the failover depends on the amount of replication lag between the primary and secondary AWS Regions.
- Manual unplanned failover – With unplanned failover, you manually detach and promote the one of the Aurora cluster in secondary Region on vary rare occasions when you experience outage in primary Region. You will then recreate Aurora global database and restore replication topology. The RTO typically less than 1 minute for the database. The RPO depends on Aurora storage replication lag across the network at the time of the failure. You can monitor how far an Aurora cluster in secondary Region is lagging behind the cluster in Primary Region by monitoring the Amazon CloudWatch
AuroraGlobalDBReplicationLagmetric.
Data replication
Replication latency can affect how quickly a service can be recovered across Regions in the event of failure. It’s also very important that the data replication is fast enough that it meets your application SLA for local reads. Aurora replicas share the same data volume as the primary instance in the same Region; there is virtually no replication lag within the Region. We typically observe lag times in the tens of milliseconds. Aurora Replicas in secondary Regions of an Aurora global database have a typical lag of under a second.
Networking
You can connect applications hosted in Amazon EKS Clusters in multiple AWS Regions over private network using AWS Transit Gateway for intra-Region VPC peering.
Scalability
Your application and database services should have natural elasticity to automatically scale as demand increases and scale back when the load subsides.
Aurora supports up to 15 low-latency read replicas across three Availability Zones in the primary Region. We can configure up to five secondary Regions and up to 16 read replicas in each secondary Region with Aurora global database. Aurora Global Database lets you scale database reads across Regions and place your applications close to your users.
Amazon EKS supports a Horizontal Pod Autoscaler for scaling out containerized applications when the CPU threshold is reached.
Traffic routing
Automatic traffic routing along with service recovery is another challenge for an enterprise when disaster strikes.
Aurora Global Database managed planned and unplanned failover require application reconfiguration to send all the write operations to Aurora DB cluster endpoint in the new primary Region. You can configure your application to use the Amazon Route 53 DNS cname record and update it to point to new writer endpoint to minimize application reconfiguration. But the DNS cname change propagation is often delayed due to time to live (TTL) and affects overall failover time. In addition, the database connections are dropped during failover and the application should reestablish connections. You can find an example solution in this GitHub repo.
In this post, we use PgBouncer database connection pooler to handle above limitation transparently during planned Aurora global database (PostgreSQL-compatible edition) failover. It helps to persist database connections during failover. We use Amazon EventBridge and AWS Lambda to handle PgBouncer reconfiguration automatically during failover. You can use open-source solutions such as ProxySQL for Aurora cluster MySQL-compatible edition. Refer to Setup highly available PgBouncer and HAProxy with Amazon Aurora PostgreSQL readers to learn more.
You can use AWS Global Accelerator or Amazon CloudFront for routing connections to applications that are available in different Regions.
Solution overview
The following architecture diagram presents an overview of the solution in this post:
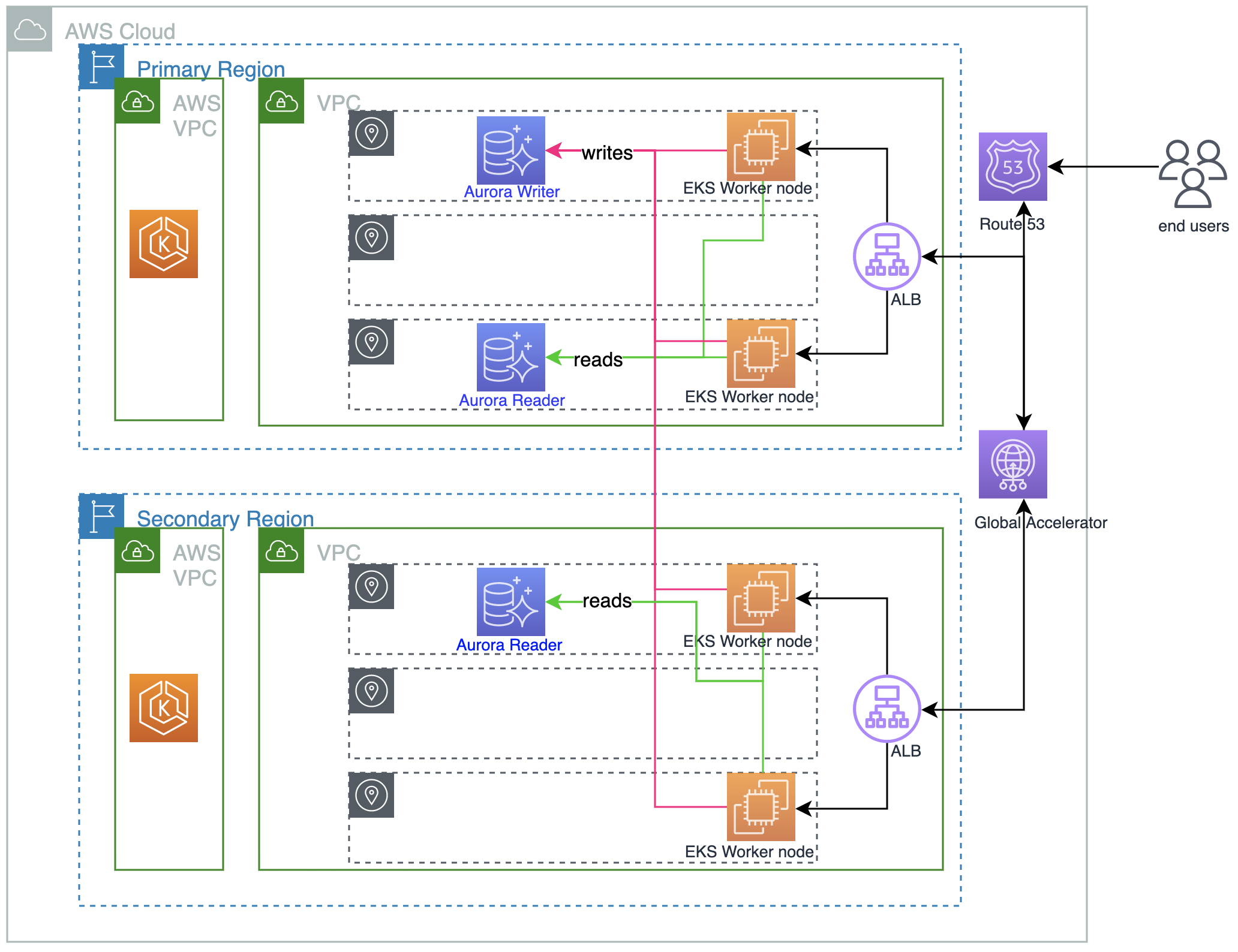
We configure both Regions to be active-active using the local read and global write design pattern. We start by creating an Amazon EKS cluster and Aurora global database with PostgreSQL compatibility in Regions us-east-2 and us-west-2. We use PgBouncer for connection pooling. We also implement a workflow for PgBouncer to handle planned Aurora global database failover. We then deploy the application stack, which includes stateful and stateless containerized applications to Amazon EKS clusters in both Regions, and exposes the application endpoint using an Application Load Balancer in the respective Regions. Finally, we configure Global Accelerator for the load balancers as endpoints.
Summary
In this post, you learned the architecture patterns and multi-Region application design.
In Part 2 of this series, we will discuss how to scale and build resiliency and automatic failover of your multi-Region applications using Amazon EKS, Global Accelerator, and Aurora Global Database.
We welcome your feedback, leave your comments or questions in the comments section.
About the Authors
 Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with AWS RDS team, focusing on Opensource database engines RDS PostgreSQL and Aurora PostgreSQL. He has over 20 years of experience in managing commercial & open source database solutions in financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with AWS RDS team, focusing on Opensource database engines RDS PostgreSQL and Aurora PostgreSQL. He has over 20 years of experience in managing commercial & open source database solutions in financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
 Sundar Raghavan is a Principal Database Specialist Solutions Architect at Amazon Web Services (AWS) and specializes in relational databases. Among his customers are clients across multiple industries in support of Oracle, PostgreSQL, and migration from Oracle to PostgreSQL on AWS. Previously, Sundar served as a database and data platform architect at Oracle, Cloudera/Horton Works. He enjoys reading, watching movies, playing chess and being outside when he is not working.
Sundar Raghavan is a Principal Database Specialist Solutions Architect at Amazon Web Services (AWS) and specializes in relational databases. Among his customers are clients across multiple industries in support of Oracle, PostgreSQL, and migration from Oracle to PostgreSQL on AWS. Previously, Sundar served as a database and data platform architect at Oracle, Cloudera/Horton Works. He enjoys reading, watching movies, playing chess and being outside when he is not working.