AWS Database Blog
Introducing 99.99% Availability with Amazon ElastiCache for Redis and Amazon MemoryDB for Redis
A managed cloud service eliminates the tedious task of managing infrastructure and offers several key benefits, including scalability, cost savings, and security. These benefits make it compelling for mission-critical applications to move to the cloud. High availability is especially important for these applications because any downtime can cause loss of revenue, impact team productivity, and reduce customer satisfaction. Recently, Amazon ElastiCache for Redis and Amazon MemoryDB for Redis rolled out an improved availability Service Level Agreement (SLA) of 99.99% for Multi-Availability Zone (Multi-AZ) configurations.
Previously, Amazon ElastiCache for Redis and MemoryDB offered a 99.9% SLA for Multi-AZ configurations. These services are designed to provide a higher level of availability compared to the public SLA. In the past year, AWS has developed more innovations in its high-availability technologies for ElastiCache and MemoryDB, including advanced monitoring, reduced failover times during primary node impairment, and expedited recovery processes. With these advancements, we have introduced a 99.99% SLA for Amazon ElastiCache for Redis and MemoryDB Multi-AZ configurations. The availability tiers offered by these services are outlined in the following table. To learn more, refer to the ElastiCache SLA and MemoryDB SLA.
| Configuration Type | Availability SLA | Max Downtime/Month |
| Single-AZ | 99.50% | 3h 37m 21s |
| Previous Generation
Multi-AZ |
99.9% | 43m 28s |
| Multi-AZ | 99.99% | 4m 21s |
Every minute of unavailability translates directly to applications being unable to serve incoming requests, so maximizing availability becomes a requirement for a high-quality user experience. Workloads that require real-time data access or processing, involve large volumes of data, or have strict uptime requirements, benefit from highly available in-memory databases. The following is what ElastiCache customer Okta, a leading identity and access management company based in San Francisco, mentioned regarding increased availability to 99.99%:
 “More than 17,000 organizations trust Okta to help them protect the identities of their customers and workforces. Providing a mission-critical service for our customers requires building stability and resiliency into every level of our stack. AWS services like ElastiCache that natively offer a 99.99% availability SLA help us to simplify complexity and deliver on the promises we make to our customers.” – Cassio Sampaio, Senior Vice President of Product at Okta.
“More than 17,000 organizations trust Okta to help them protect the identities of their customers and workforces. Providing a mission-critical service for our customers requires building stability and resiliency into every level of our stack. AWS services like ElastiCache that natively offer a 99.99% availability SLA help us to simplify complexity and deliver on the promises we make to our customers.” – Cassio Sampaio, Senior Vice President of Product at Okta.
The updated SLA is available for our most recent ElastiCache for Redis and MemoryDB engine versions in all applicable regions where these services are generally available. In this post, we demonstrate how to get started with the 99.99% availability SLA for ElastiCache and MemoryDB.
Ensure higher availability with ElastiCache for Redis
Enabling the Multi-AZ option improves fault tolerance and enhances the availability of your cluster. With Multi-AZ enabled, ElastiCache for Redis will place the primary and at least one replica node of each cluster shard in different Availability Zones. In the event of primary node impairment, ElastiCache will automatically promote the read replica with the least replication lag to be the new primary within a few seconds. The service then self-heals the impaired primary node or replaces it with a new replica node, and synchronizes the data from the new primary. For more information see Failure scenarios with Multi-AZ responses.
ElastiCache for Redis Multi-AZ Clusters created after January 13, 2023 and running ElastiCache for Redis Version 6.2 or later are automatically eligible for the updated 99.99% SLA. For clusters created before this date, you can apply a recent engine service update to ensure SLA eligibility.
In the following sections, we walk through how to ensure 99.99% SLA eligibility for ElastiCache for Redis clusters via the console and the AWS CLI.
Verify that your ElastiCache for Redis clusters are eligible for 99.99% SLA through the console
To verify the eligibility of your ElastiCache for Redis clusters using the console, complete the steps in this section.
Verify that Multi-AZ is enabled
There are two ways of checking that Multi-AZ is enabled on your ElastiCache clusters using the console:
- Through the Trusted Advisor console
- Through the ElastiCache console
Verify that Multi-AZ is enabled through AWS Trusted Advisor Console
If you have multiple ElastiCache for Redis clusters, the easiest approach for checking if Multi-AZ is inactive on your clusters is by logging in to the AWS Trusted Advisor console and viewing the fault tolerance checks. A green status means that Multi-AZ is active in the cluster. A yellow status means that Multi-AZ is inactive.
Note that the AWS Trusted Advisor fault tolerance checks take 24 hours to accurately reflect if Multi-AZ is active or inactive in a cluster. In addition, the fault tolerance checks are visible for customers on Business, Enterprise On-Ramp, or Enterprise support plans. For more information, refer AWS support plans.

Verify that Multi-AZ is enabled through ElastiCache Console
You can check if Multi-AZ is enabled in the ElastiCache console with the following steps:
- On the ElastiCache console, choose Redis Clusters on the navigation pane.
- On the Resources tab, choose the individual cluster to view its details.
- Under Cluster details, check under Multi-AZ to see if it’s enabled.

If Multi-AZ is not enabled, ensure that a primary and replica set in each shard is deployed in at least two separate Availability Zones before enabling Multi-AZ. You can then enable Multi-AZ by modifying your cluster. For more information on this process, refer to the Using the AWS Management Console section of Modifying an ElastiCache cluster.
Verify that ElastiCache for Redis clusters are running ElastiCache for Redis version 6.2 or later
On the same Redis clusters page in the ElastiCache console, you can also check if the applicable clusters are running on ElastiCache for Redis version 6.2 or later under Engine version.

If the engine version is below ElastiCache for Redis version 6.2, you can upgrade to a newer engine version by modifying the cluster. For more information on this process, refer to the Using the AWS Management Console section of Modifying an ElastiCache cluster.
Verify that the latest engine service update released after January 13, 2023, is installed on Redis Multi-AZ clusters
If you created an ElastiCache for Redis cluster running Redis version 6.2 or later, or upgraded an existing cluster to Redis version 6.2 or later after January 13, 2023, you can skip this step.
To check if your ElastiCache for Redis clusters are running the latest engine service update released after January 13, 2023.
- Choose an applicable cluster on the Redis Clusters page.
- Choose Service updates in the navigation pane to see the applicable service updates for that cluster, if any. You can then filter by the release date to see the latest engine service update after January 13th, 2023.
If the console displays a list of service updates, you can select the engine service update released after January 13th, and choose Apply now.

If the console displays “No service updates found”, it means the ElastiCache for Redis cluster already has the latest engine service update applied and no further action is required.

Verify that your ElastiCache for Redis clusters are eligible for 99.99% SLA availability through the AWS CLI
In this section, we walk through the three-step verification process using the AWS CLI.
Verify that Multi-AZ is enabled
You can check if Multi-AZ is enabled for your replication groups through the AWS CLI by running the following command:
The JSON output from this command should look something like the following example code. The MultiAZ flag indicates if you have Multi-AZ enabled to enhance fault tolerance. For more information, refer to the AWS CLI describe-replication-groups command.
If you notice Multi-AZ is disabled after running the describe command, ensure that a primary and replica set in each shard is deployed in at least two separate Availability Zones before enabling Multi-AZ. You can then enable Multi-AZ by modifying your cluster. For more information on this process, see Enable Multi-AZ (AWS CLI).
Verify that ElastiCache for Redis clusters are running ElastiCache for Redis version 6.2 or later
You can check if your ElastiCache for Redis clusters are running ElastiCache for Redis version 6.2 or later by running the following command:
The JSON output from this command should look something like the following code. The EngineVersion attribute refers to the cache engine version that the cluster is running on. For more information, refer to the AWS CLI describe-cache-clusters command.
If the engine version is below ElastiCache for Redis version 6.2, you can initiate version upgrades to your cluster or replication group by modifying it using the AWS CLI and specifying a newer engine version. For more information, see How to upgrade engine versions.
Verify that the latest engine service update is installed on the Redis Multi-AZ clusters
If you created a ElastiCache for Redis cluster running Redis version 6.2 or later, or upgraded an existing cluster to Redis version 6.2 or later after January 13, 2023, you can skip this step.
To retrieve a description of the service updates that are available for your replication group with ElastiCache for Redis version 6.2 or later, run the following command on the AWS CLI:
Refer to the ServiceUpdateReleaseDate and ServiceUpdateType attributes to validate that you’re applying an engine service update released after January 13, 2023. In addition, you can use the UpdateActionStatus attribute to determine if the applicable service update has not been applied yet. If you have pending engine service updates to be applied to your replication group, the output will look similar to the following code:
If your replication group is running on the latest engine service update and there are no pending service updates to be applied, you will get an output similar to the following code:
You can apply the applicable service update to your replication group by running the following command:
For more information on these AWS CLI commands, refer the describe-update-actions and batch-apply-update-action documentation.
Ensure higher availability with MemoryDB
When you launch a MemoryDB cluster, the Multi-AZ option will be automatically enabled when you have at least one replica per shard. In the event of primary node impairment, MemoryDB will automatically promote the lowest latency replica node as a new primary within a few seconds. If it’s unable to self-heal the impaired node, MemoryDB will provision a new node, and synchronizes the data from the new primary using its distributed transaction log. Refer to Failure scenarios with Multi-AZ responses to learn more about the behavior and action taken by MemoryDB. All MemoryDB Multi-AZ clusters are automatically eligible for the updated SLA, with no action required.
In the following sections, we demonstrate how to ensure that a MemoryDB cluster is configured with Multi-AZ through the console and the AWS CLI.
Verify that your existing MemoryDB clusters are using Multi-AZ through the console
On the AWS Console, you can verify that Multi-AZ is enabled for your MemoryDB clusters either through Trusted Advisor console or MemoryDB console. The AWS Trusted Advisor fault tolerance check determines if your clusters are running in a Single-AZ configuration and provides recommendations on how to enable Multi-AZ with automatic failover in your MemoryDB Cluster. To learn more, refer the above section on Verifying that Multi-AZ is enabled through AWS Trusted Advisor Console.
To verify using the MemoryDB console, follow the below steps.
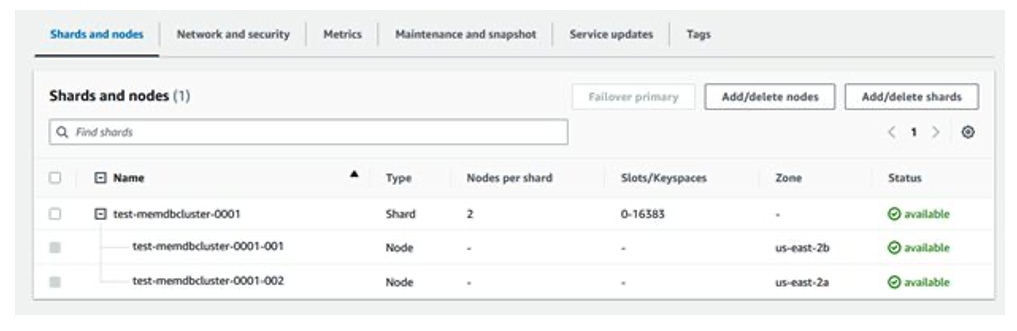
- On the MemoryDB console, choose Clusters in the navigation pane.
- Choose the applicable cluster you want to check.
- On the Shards and nodes tab, examine the Nodes per shard column.
If the value is ≥ 2, Multi-AZ is enabled. When provisioning clusters, MemoryDB acts on behalf of the customer to replicate nodes in multiple Availability Zones in a selected Region when the number of nodes ≥ 2. All MemoryDB Multi-AZ clusters are eligible for the 99.99% availability SLA.
Verify that your existing MemoryDB clusters are using Multi-AZ through the AWS CLI
To verify that your MemoryDB Multi-AZ cluster is eligible through the AWS CLI, you have to check if Multi-AZ is enabled for each of your clusters. Once your AWS account is configured on the AWS CLI, run the following command:
This will return an JSON output similar to the following example code. The attribute you are looking for in each cluster is NumberOfNodes. If the value is ≥ 2, Multi-AZ is enabled. As we stated before, when provisioning clusters, MemoryDB replicates nodes in multiple Availability Zones in a selected Region when the number of nodes ≥ 2. All MemoryDB Multi-AZ clusters are eligible for the 99.99% availability SLA.
Best practices for higher availability
Even when using a service like ElastiCache or MemoryDB that provides 99.99% availability, it’s important that you follow best practices while building applications. Following best practices with ElastiCache caching strategies, Redis clients, and MemoryDB further enhances the availability and resiliency of the overall application. You can test your application’s ability to handle failovers effectively by following testing automatic failover for ElastiCache for Redis clusters and testing automatic failover for MemoryDB for Redis clusters.
Summary
AWS is committed to providing higher availability for our services by making continuous enhancements to our monitoring and internal recovery mechanisms. This will greatly help you strengthen your critical applications with high availability and resiliency in the AWS Cloud. In this post, we highlighted what it means to have 99.99% availability with ElastiCache for Redis and MemoryDB. We also showed how you can configure your ElastiCache for Redis and MemoryDB clusters to get the enhanced availability of 99.99%. Refer ElastiCache SLA and MemoryDB SLA to know more about the increased availability.
About the Authors
 CJ Chittajallu is a Technical Program Manager for Amazon ElastiCache and Amazon MemoryDB. He has an extensive background in management consulting, cloud migrations, cloud engineering, and digital strategy. He is passionate about Cloud, AI/ML, and works closely with customers on their digital transformation journeys.
CJ Chittajallu is a Technical Program Manager for Amazon ElastiCache and Amazon MemoryDB. He has an extensive background in management consulting, cloud migrations, cloud engineering, and digital strategy. He is passionate about Cloud, AI/ML, and works closely with customers on their digital transformation journeys.
 Mahesh Cherukumilli is a Software Development Manager for Amazon ElastiCache and Amazon MemoryDB, where he manages a development team with a focus on creating a monitoring and remediation system that sustains a highly available in-memory database. Mahesh demonstrates a strong passion for building a database that is both highly available and cost-efficient, while also delivering outstanding performance, in order to assist customers with workloads that require real-time data access or processing and involves large volumes of data.
Mahesh Cherukumilli is a Software Development Manager for Amazon ElastiCache and Amazon MemoryDB, where he manages a development team with a focus on creating a monitoring and remediation system that sustains a highly available in-memory database. Mahesh demonstrates a strong passion for building a database that is both highly available and cost-efficient, while also delivering outstanding performance, in order to assist customers with workloads that require real-time data access or processing and involves large volumes of data.
 Shirish Kulkarni is a Solutions Architect specialized in In-Memory NoSQL databases based in Sydney, Australia. He has more than a decade of experience working with various NoSQL databases and architecting highly scalable applications with distributed technologies. He is highly passionate about NoSQL databases and loves helping customers to choose the right database for their use case. In his free time, you can see him spending time outdoors playing with his twin kids.
Shirish Kulkarni is a Solutions Architect specialized in In-Memory NoSQL databases based in Sydney, Australia. He has more than a decade of experience working with various NoSQL databases and architecting highly scalable applications with distributed technologies. He is highly passionate about NoSQL databases and loves helping customers to choose the right database for their use case. In his free time, you can see him spending time outdoors playing with his twin kids.
 Madelyn Olson is a maintainer of the OSS Redis project and a Software Development Engineer at Amazon ElastiCache and Amazon MemoryDB, focusing on building secure and highly reliable features for the Redis engine. In her free time she enjoys taking in the natural beauty of the pacific northwest with long hikes and serene bike rides.
Madelyn Olson is a maintainer of the OSS Redis project and a Software Development Engineer at Amazon ElastiCache and Amazon MemoryDB, focusing on building secure and highly reliable features for the Redis engine. In her free time she enjoys taking in the natural beauty of the pacific northwest with long hikes and serene bike rides.
 Sandeep Palur is a Software Development Manager at Amazon ElastiCache and Amazon MemoryDB, where he manages the high availability and reliability team. He has extensive experience in developing and operating large-scale distributed systems, in-memory databases, and cloud-integrated storage systems. In his free time he enjoys sports, hiking, and spending time with his family.
Sandeep Palur is a Software Development Manager at Amazon ElastiCache and Amazon MemoryDB, where he manages the high availability and reliability team. He has extensive experience in developing and operating large-scale distributed systems, in-memory databases, and cloud-integrated storage systems. In his free time he enjoys sports, hiking, and spending time with his family.