AWS Compute Blog
Understanding data streaming concepts for serverless applications
Amazon Kinesis is a suite of managed services that can help you collect, process, and analyze streaming data in near-real time. It consists of four separate services that are designed for common tasks with streaming data: This blog post focuses on Kinesis Data Streams.
One of the main benefits of processing streaming data is that an application can react as new data is generated, instead of waiting for batches. This real-time capability enables new functionality for applications. For example, payment processors can analyze payments in real time to detect fraudulent transactions. Ecommerce websites can use streams of clickstream activity to determine site engagement metrics in near-real time.
Kinesis can be used with Amazon EC2-based and container-based workloads. However, its integration with AWS Lambda can make it a useful data source for serverless applications. Using Lambda as a stream consumer can also help minimize the amount of operational overhead for managing streaming applications.
In this post, I explain important streaming concepts and how they affect the design of serverless applications. This post references the Alleycat racing application. Alleycat is a home fitness system that allows users to compete in an intense series of 5-minute virtual bicycle races. Up to 1,000 racers at a time take the saddle and push the limits of cadence and resistance to set personal records and rank on leaderboards. The Alleycat software connects the stationary exercise bike with a backend application that processes the data from thousands of remote devices.
The Alleycat frontend allows users to configure their races and view real-time leaderboard and historical rankings. The frontend could wait until the end of each race and collect the total output from each racer. Once the batch is ready, it could rank the results and provide a leaderboard once the race is completed. However, this is not very engaging for competitors. By using streaming data instead of a batch, the application show the racers a view of who is winning during the race. This makes the virtual environment more like a real-life cycling race.
Producers and consumers
In streaming data workloads, producers are the applications that produce data and consumers are those that process it. In a serverless streaming application, a consumer is usually a Lambda function, Amazon Kinesis Data Firehose, or Amazon Kinesis Data Analytics.
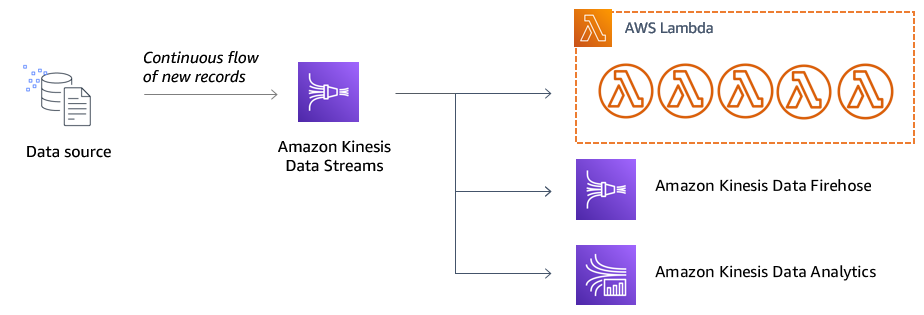
There are a number of ways to put data into a Kinesis stream in serverless applications, including direct service integrations, client libraries, and the AWS SDK.
|
Producer |
Kinesis Data Streams |
Kinesis Data Firehose |
| Amazon CloudWatch Logs | Yes, using subscription filters | Yes, using subscription filters |
| AWS IoT Core | Yes, using IoT rule actions | Yes, using IoT rule actions |
| AWS Database Migration Service | Yes – set stream as target | Not directly. |
| Amazon API Gateway | Yes, via REST API direct service integration | Yes, via REST API direct service integration |
| AWS Amplify | Yes – via JavaScript library | Not directly |
| AWS SDK | Yes | Yes |
A single stream may have tens of thousands of producers, which could be web or mobile applications or IoT devices. The Alleycat application uses the AWS IoT SDK for JavaScript to publish messages to an IoT topic. An IoT rule action then uses a direct integration with Kinesis Data Streams to push the data to the stream. This configuration is ideal at the device level, especially since the device may already use AWS IoT Core to receive messages.
The Alleycat simulator uses the AWS SDK to send a large number of messages to the stream. The SDK provides two methods: PutRecord and PutRecords. The first allows you to send a single record, while the second supports up to 500 records per request (or up to 5 MB in total). The simulator uses the putRecords JavaScript API to batch messages to the stream.
A producer can put records directly on a stream, for example via the AWS SDK, or indirectly via other services such as Amazon API Gateway or AWS IoT Core. If direct, the producer must have appropriate permission to write data to the stream. If indirect, the producer must have permission to invoke the proxy service, and then the service must have permission to put data onto the stream.
While there may be many producers, there are comparatively fewer consumers. You can register up to 20 consumers per data stream, which share the outgoing throughout limit per shard. Consumers receive batches of records sequentially, which means processing latency increases as you add more consumers to a stream. For latency-sensitive applications, Kinesis offers enhanced fan-out which gives consumers 2 MB per second dedicated throughput and uses a push model to reduce latency.
Shards, streams, and partition keys
A shard is a sequence of data records in a stream with a fixed capacity. Part of Kinesis billing is based upon the number of shards. A single shard can process up to 1 MB per second or 1,000 records of incoming data. One shard can also send up to 2 MB per second of outgoing data to downstream consumers. These are hard limits on the throughputs of a shard and as your application approaches these limits, you must add more shards to avoid exceeding these limits.
A stream is a collection of these shards and is often a grouping at the workload or project level. Adding another shard to a stream effectively doubles the throughput, though it also doubles the cost. When there is only one shard in a stream, all records sent to that sent are routed to the same shard. With multiple shards, the routing of incoming messages to shards is determined by a partition key.
The data producer adds the partition key before sending the record to Kinesis. The service calculates an MD5 hash of the key, which maps to one of the shards in the stream. Each shard is assigned a range of non-overlapping hash values, so each partition key maps to only one shard.
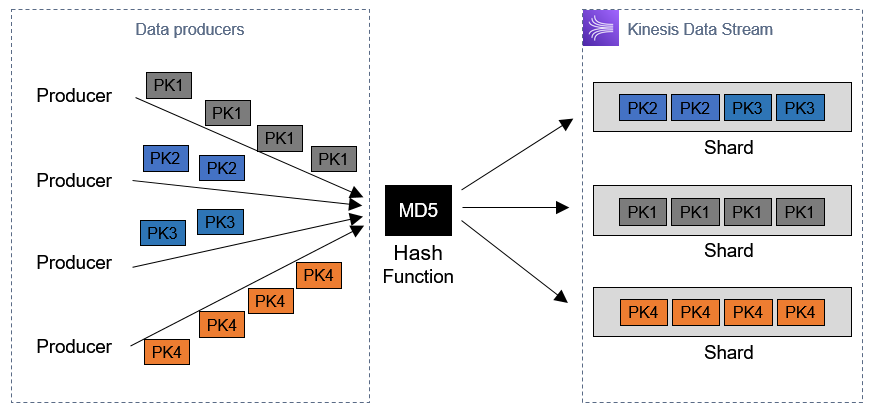
The partition key exists as an alternative to specifying a shard ID directly, since it’s common in production applications to add and remove shards depending upon traffic. How you use the partition key determines the shard-mapping behavior. For example:
- Same value: If you specify the same string as the partition key, every message is routed to a single shard, regardless of the number of shards in the stream. This is called overheating a shard.
- Random value: Using a pseudo-random value, such as a UUID, evenly distributes messages between all the shards available.
- Time-based: Using a timestamp as a partition key may result in a preference for a single shard if multiple messages arrive at the same time.
- Application–specific: The Alleycat application uses the raceId as a partition key to ensure that all messages from a single race are processed by the same shard consumer.
A Lambda function is a consumer application for a data stream and processes one batch of records for each shard. Since Alleycat uses a tumbling window to calculate aggregates between batches, this use of the partition key ensures that all messages for each raceId are processed by the same function. The downside to this architecture is that it is limited to 1,000 incoming messages per second with the same raceId since it is bound to a single shard.
Deciding on a partition key strategy depends upon the specific needs of your workload. In most cases, a random value partition key is often the best approach.
Streaming payloads in serverless applications
When using the SDK to put messages to a stream, the Data attribute can be a buffer, typed array, blob, or string. Combined with the partition key value, the maximum record size is 1 MB. The Data value is base64 encoded when serialized by Kinesis and delivered as an encoded value to downstream consumers. When using a Lambda function consumer, Kinesis delivers batches in a Records array. Each record contains the encoded data attribute, partition key, and additional metadata in a JSON envelope:

Ordering and idempotency
Records in a Kinesis stream are delivered to consuming applications in the same order that they arrive at the Kinesis service. The service assigns a sequence number to the record when it is received and this is delivered as part of the payload to a Kinesis consumer:
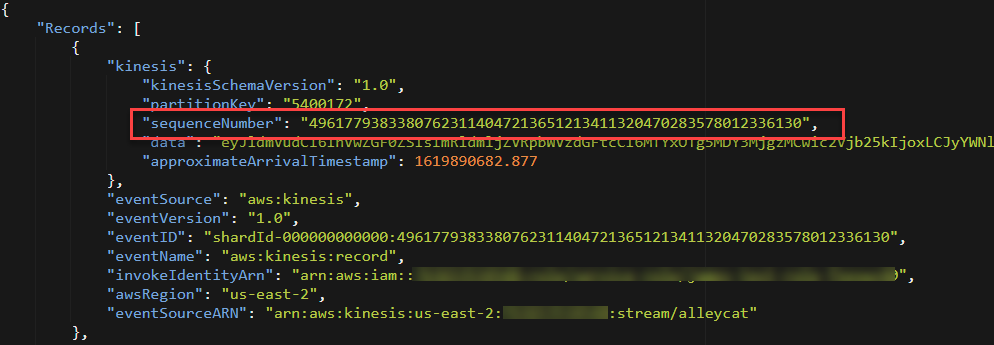
When using Lambda as a consuming application for Kinesis, by default each shard has a single instance of the function processing records. In this case, ordering is guaranteed as Kinesis invokes the function serially, one batch of records at a time.

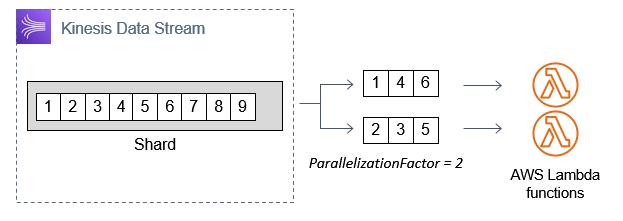
You can increase the number of concurrent function invocations by setting the ParallelizationFactor on the event source mapping. This allows you to set a concurrency of between 1 and 10, which provides a way to increase Lambda throughout if the IteratorAge metric is increasing. However, one side effect is that ordering per shard is no longer guaranteed, since the shard’s messages are split into multiple subgroups based upon an internal hash.
Kinesis guarantees that every record is delivered “at least once”, but occasionally messages are delivered more than once. This is caused by producers that retry messages, network-related timeouts, and consumer retries, which can occur when worker processes restart. In both cases, these are normal activities and you should design your application to handle infrequent duplicate records.
To prevent the duplicate messages causing unintentional side effects, such as charging a payment twice, it’s important to design your application with idempotency in mind. By using transaction IDs appropriately, your code can determine if a given message has been processed previously, and ignore any duplicates. In the Alleycat application, the aggregation and processes of messages is idempotent. If two identical messages are received, processing completes with the same end result.
To learn more about implementing idempotency in serverless applications, read the “Serverless Application Lens: AWS Well-Architected Framework”.
Conclusion
In this post, I introduce some of the core streaming concepts for serverless applications. I explain some of the benefits of streaming architectures and how Kinesis works with producers and consumers. I compare different ways to ingest data, how streams are composed of shards, and how partition keys determine which shard is used. Finally, I explain the payload formats at the different stages of a streaming workload, how message ordering works with shards, and why idempotency is important to handle.
To learn more about building serverless web applications, visit Serverless Land.