AWS Big Data Blog
Tag: DevOps

Build, Test and Deploy ETL solutions using AWS Glue and AWS CDK based CI/CD pipelines
April 2025: After careful consideration, we have made the decision to close new customer access to AWS CodeCommit, effective July 25, 2024. AWS CodeCommit existing customers can continue to use the service as normal. AWS continues to invest in security, availability, and performance improvements for AWS CodeCommit, but we do not plan to introduce new […]
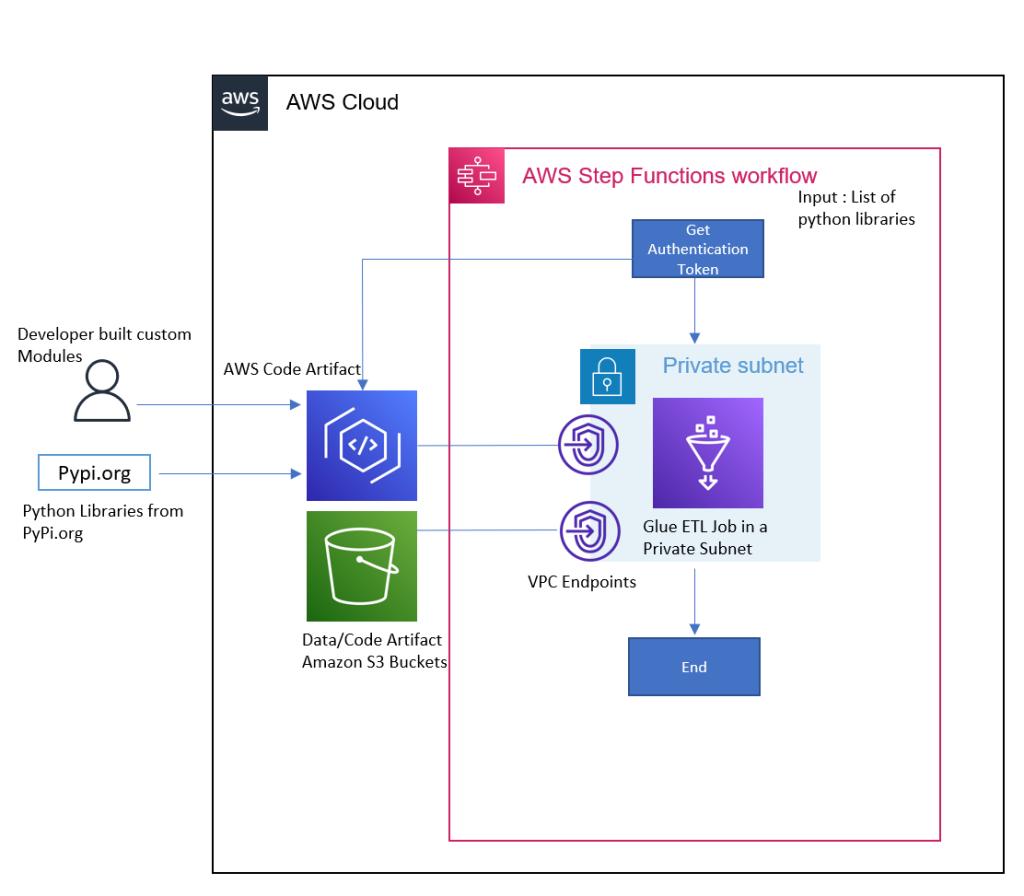
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]