AWS Big Data Blog
Tag: AWS Analytics

Export JMX metrics from Kafka connectors in Amazon Managed Streaming for Apache Kafka Connect with a custom plugin
In this post, we demonstrate how you can export the JMX metrics for Debezium connector when used with Amazon MSK Connect.

Use Databricks Unity Catalog Open APIs for Spark workloads on Amazon EMR
In this post, we demonstrate the powerful interoperability between Amazon EMR and Databricks Unity Catalog by walking through how to enable external access to Unity Catalog, configure EMR Spark to connect seamlessly with Unity Catalog, and perform DML and DDL operations on Unity Catalog tables using EMR Serverless.

Read and write Apache Iceberg tables using AWS Lake Formation hybrid access mode
In this post, we demonstrate how to use Lake Formation for read access while continuing to use AWS Identity and Access Management (IAM) policy-based permissions for write workloads that update the schema and upsert (insert and update combined) data records into the Iceberg tables.

Unlock the power of optimization in Amazon Redshift Serverless
In this post, we demonstrate how Amazon Redshift Serverless AI-driven scaling and optimization impacts performance and cost across different optimization profiles.

How Getir unleashed data democratization using a data mesh architecture with Amazon Redshift
In this post, we explain how ultrafast delivery pioneer, Getir, unleashed the power of data democratization on a large scale through their data mesh architecture using Amazon Redshift. We start by introducing Getir and their vision—to seamlessly, securely, and efficiently share business data across different teams within the organization for BI, extract, transform, and load (ETL), and other use cases. We’ll then explore how Amazon Redshift data sharing powered the data mesh architecture that allowed Getir to achieve this transformative vision.

Apply fine-grained access and transformation on the SUPER data type in Amazon Redshift
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per […]

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless
This is a guest post co-written with Mukul Sharma, Software Development Engineer, and Ozcan IIikhan, Director of Engineering from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, […]

Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other […]
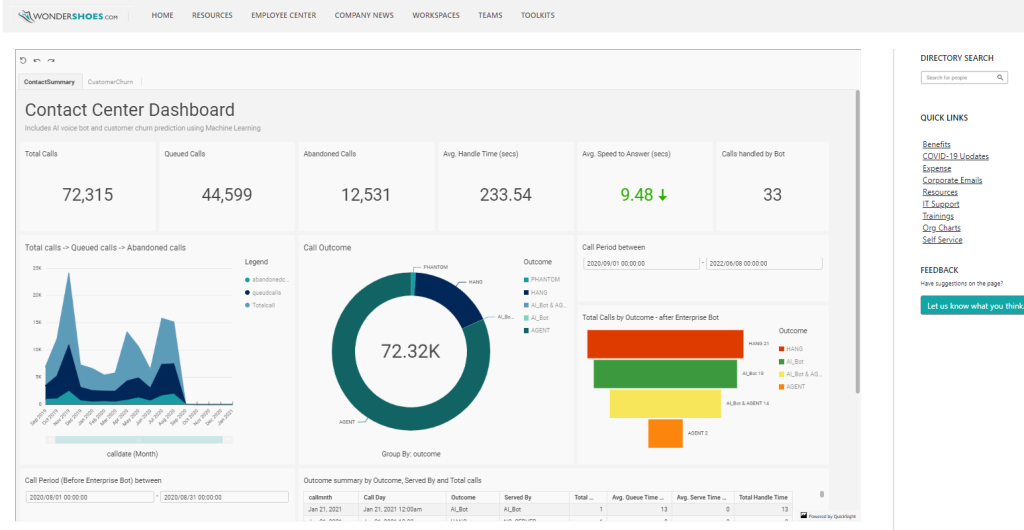
Top Amazon QuickSight features launched in Q2 2022
Amazon QuickSight is a serverless, cloud-based business intelligence (BI) service that brings data insights to your teams and end-users through machine learning (ML)-powered dashboards and data visualizations, which can be accessed via QuickSight or embedded in apps and portals that your users access. This post shares the top QuickSight features and updates launched in Q2 […]