AWS Big Data Blog
Tag: Apache Iceberg

AWS Glue Data Catalog supports automatic optimization of Apache Iceberg tables through your Amazon VPC
The AWS Glue Data Catalog supports automatic table optimization of Apache Iceberg tables, including compaction, snapshots, and orphan data management. The data compaction optimizer constantly monitors table partitions and kicks off the compaction process when the threshold is exceeded for the number of files and file sizes. This post demonstrates how it works with step-by-step instructions.

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]

Accelerate query performance with Apache Iceberg statistics on the AWS Glue Data Catalog
August 2024: This post was updated with Amazon Athena support. Today, we are pleased to announce a new capability for the AWS Glue Data Catalog: generating column-level aggregation statistics for Apache Iceberg tables to accelerate queries. These statistics are utilized by cost-based optimizer (CBO) in Amazon Redshift Spectrum and Amazon Athena, resulting in improved query performance […]

Understanding Apache Iceberg on AWS with the new technical guide
We’re excited to announce the launch of the Apache Iceberg on AWS technical guide. Whether you are new to Apache Iceberg on AWS or already running production workloads on AWS, this comprehensive technical guide offers detailed guidance on foundational concepts to advanced optimizations to build your transactional data lake with Apache Iceberg on AWS.
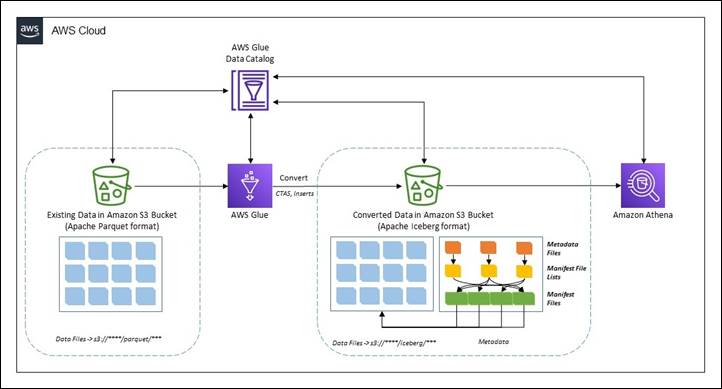
Migrate an existing data lake to a transactional data lake using Apache Iceberg
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Over the years, data lakes on Amazon Simple Storage […]

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.

Perform upserts in a data lake using Amazon Athena and Apache Iceberg
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your data lake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable). Apache Iceberg is an open table format for data lakes that manages large collections of files as […]

Use Apache Iceberg in a data lake to support incremental data processing
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has […]

Build a real-time GDPR-aligned Apache Iceberg data lake
Data lakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a data lake design, data should be immutable once stored. But regulations such as the General Data Protection Regulation (GDPR) have created obligations for data operators who must be able to erase or […]