AWS Big Data Blog
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post shares Intuit’s learnings and recommendations for running a data lake on AWS. The Intuit Data Lake is built and operated by numerous teams in Intuit Data Platform. Thanks to Tristan Baker (Chief Architect), Neil Lamka (Principal Product Manager), Achal Kumar (Development Manager), Nicholas Audo, and Jimmy Armitage for their feedback and support.
A data lake is a centralized repository for storing structured and unstructured data at any scale. At Intuit, creating such a pile of raw data is easy. However, more interesting challenges present themselves:
- How should AWS accounts be organized?
- What ingestion methods will be used? How will analysts find the data they need?
- Where should data be stored? How should access be managed?
- What security measures are needed to protect Intuit’s sensitive data?
- Which parts of this ecosystem can be automated?
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation).
We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.
Architecture
Account Structure
Data lakes typically follow a hub-and-spoke model, with the hub account containing shared services that control access to data sources. For the purposes of this post, we’ll refer to the hub account as Central Data Lake.
In this pattern, access to Central Data Lake is apportioned to spoke accounts called Processing Accounts. This model maintains separation between end users and allows for division of billing among distinct business units.
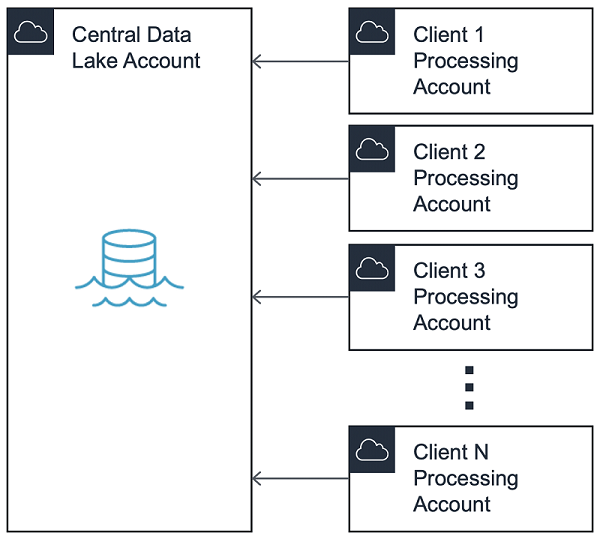
It is common to maintain two ecosystems: pre-production (Pre-Prod) and production (Prod). This allows data lake administrators to silo access to data by preventing connectivity between Pre-Prod and Prod.
To enable experimentation and testing, it may also be advisable to maintain separate VPC-based environments within Pre-Prod accounts, such as dev, qa, and e2e. Processing Account VPCs would then be connected to the corresponding VPC in Central Data Lake.
Note that at first, we connected accounts via VPC Peering. However, as we scaled we quickly approached the hard limit of 125 VPC peering connections, requiring us to migrate to AWS Transit Gateway. As of this writing, we connect multiple new Processing Accounts weekly.

Central Data Lake
There may be numerous services running in a hub account, but we’ll focus on the aspects that are most relevant to this blog: ingestion, sanitization, storage, and a data catalog.
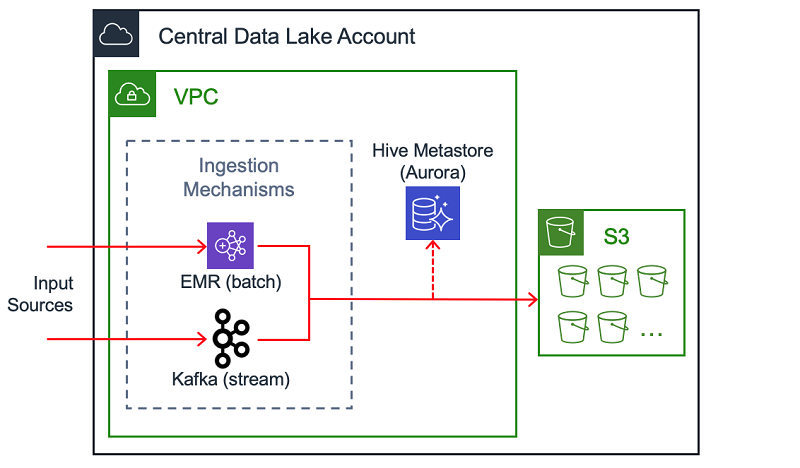
Ingestion, Sanitization, and Storage
A key component to Central Data Lake is a uniform ingestion pattern for streaming data. One example is an Apache Kafka cluster running on Amazon EC2. (You can read about how Intuit engineers do this in another AWS blog.) As we deal with hundreds of data sources, we’ve enabled access to ingestion mechanisms via AWS PrivateLink.
Note: Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an alternative for running Apache Kafka on Amazon EC2, but was not available at the start of Intuit’s migration.
In addition to stream processing, another method of ingestion is batch processing, such as jobs running on Amazon EMR. After data is ingested by one of these methods, it can be stored in Amazon S3 for further processing and analysis.
Intuit deals with a large volume of customer data, and each field is carefully considered and classified with a sensitivity level. All sensitive data that enters the lake is encrypted at the source. The ingestion systems retrieve the encrypted data and move it into the lake. Before it is written to S3, the data is sanitized by a proprietary RESTful service. Analysts and engineers operating within the data lake consume this masked data.
Data Catalog
A data catalog is a common way to give end users information about the data and where it lives. One example is a Hive Metastore backed by Amazon Aurora. Another alternative is the AWS Glue Data Catalog.
Processing Accounts
When Processing Accounts are delivered to end users, they include an identical set of resources. We’ll discuss the automation of Processing Accounts below, but the primary components are as follows:
- Connectivity to Central Data Lake via Transit Gateway
- Bastion host for SSH access to Amazon EMR clusters
- IAM roles, S3 buckets, and AWS Key Management Services (KMS) keys
- Security framework via a configuration management tool
- AWS Service Catalog products to facilitate the provisioning of Amazon EMR and Amazon SageMaker

Processing Account structure upon delivery to the customer
Data Storage Mechanisms
One reasonable question is whether all data should reside in Central Data Lake, or if it’s acceptable to distribute data across multiple accounts. A data lake might employ a combination of the two approaches, and classify data locations as primary or secondary.
The primary location for data is Central Data Lake, and it arrives there via the ingestion pipelines discussed previously. Processing Accounts can read from the primary source, either directly from the ingestion pipelines or from S3. Processing Accounts can contribute their transformed data back into Central Data Lake (primary), or store it in their own accounts (secondary). The proper storage location depends on the type of data, and who needs to consume it.
One rule worth enforcing is that no cross-account writes should be permitted. In other words, the IAM principal (in most cases, an IAM role assumed by EC2 via an instance profile) must be in the same account as the destination S3 bucket. This is because cross-account delegation is not supported—specifically, S3 bucket policies in Central Data Lake cannot grant Processing Account A access to objects written by a role in Processing Account B.
Another possibility is for EMR to assume different IAM roles via a custom credentials provider (see this AWS blog), but we chose not to go down this path at Intuit because it would have required many EMR jobs to be rewritten.
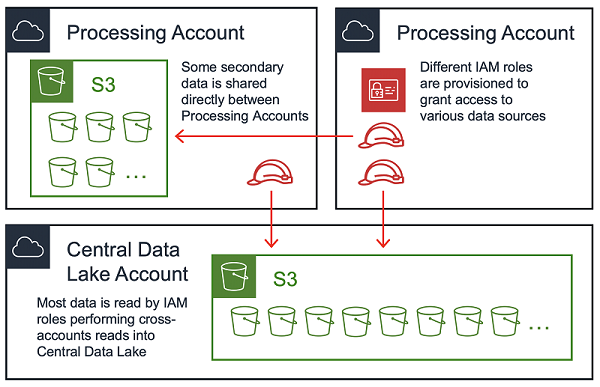
Data Access Patterns
The majority of end users are interested in the data that resides in S3. In Central Data Lake and some Processing Accounts, there may be a set of read-only S3 buckets: any account in the data lake ecosystem can read data from this type of bucket.
To facilitate management of S3 access for read-only buckets, we built a mechanism to control S3 bucket policies, administered entirely via code. Our deployment pipelines use account metadata to dynamically generate the correct S3 bucket policy based on the type of account (Pre-Prod or Prod). These policies are committed back into our code repository for auditability and ease of management.
We employ the same method for managing KMS key policies, as we use KMS with customer managed customer master keys (CMKs) for at-rest encryption in S3.
Here’s an example of a generated S3 bucket policy for a read-only bucket:
Note that we grant access at the account level, rather than using explicit IAM principal ARNs. Because the reads are cross-account, permissions are also required on the IAM principals in Processing Accounts. Maintaining these policies—with automation, at that level of granularity—is untenable at scale. Furthermore, using specific IAM principal ARNs would create an external dependency on foreign accounts. For example, if a Processing Account deletes an IAM role that is referenced in an S3 bucket policy in Central Data Lake, the bucket policy can no longer be saved, causing interruptions to deployment pipelines.
Security
Security is mission critical for any data lake. We’ll mention a subset of the controls we use, but not dive deep.
Encryption
Encryption can be enforced both in transit and at rest, using multiple methods:
- Traffic within the lake should use the latest version of TLS (1.2 as of this writing)
- Data can be encrypted with application-level (client-side) encryption
- KMS keys can used for at-rest encryption of S3, EBS, and RDS
Ingress and Egress
There’s nothing out of the ordinary in our approach to ingress and egress, but it’s worth mentioning the standard patterns we’ve found important:
- Use bastion hosts with security groups limiting SSH traffic to appropriate CIDR ranges
- Prevent unwanted data egress with network access control lists (ACLs)
- Route access to S3 buckets via VPC endpoints to avoid going over the public internet
Policies restricting ingress and egress are the primary points at which a data lake can guarantee quality (ingress) and prevent loss (egress).
Authorization
Access to the Intuit Data Lake is controlled via IAM roles, meaning no IAM users (with long-term credentials) are created. End users are granted access via an internal service that manages role-based, federated access to AWS accounts. Regular reviews are conducted to remove nonessential users.
Configuration Management
We use an internal fork of Cloud Custodian, which is a suite of preventative, detective, and responsive controls consisting of Amazon CloudWatch Events and AWS Config rules. Some of the violations it reports and (optionally) mitigates include:
- Unauthorized CIDRs in inbound security group rules
- Public S3 bucket policies and ACLs
- IAM user console access
- Unencrypted S3 buckets, EBS volumes, and RDS instances
Lastly, Amazon GuardDuty is enabled in all Intuit Data Lake accounts and is monitored by Intuit Security.
Automation
If there is one thing we’ve learned building the Intuit Data Lake, it is to automate everything.
There are four areas of automation we’ll discuss in this blog:
- Creation of Processing Accounts
- Processing Account Orchestration Pipeline
- Processing Account Terraform Pipeline
- EMR and SageMaker deployment via Service Catalog
Creation of Processing Accounts
The first step in creating a Processing Account is to make a request through an internal tool. This triggers automation that provisions an Intuit-stamped AWS account under the correct business unit.

Note: AWS Control Tower’s Account Factory was not available at the start of our journey, but it can be leveraged to provision new AWS accounts in a secured, best practice, self-service way.
Account setup also includes automated VPC creation (with optional VPN), fully automated using Service Catalog. End users simply specify subnet sizes.
It’s worth noting that Intuit leverages Service Catalog for self-service deployment of other common patterns, including ingress security groups, VPC endpoints, and VPC peering. Here’s an example portfolio:

Processing Account Orchestration Pipeline
After account creation and VPC provisioning, the Processing Account Orchestration Pipeline runs. This pipeline executes one-time tasks required for Processing Accounts. These tasks include:
- Bootstrapping an IAM role for use in further configuration management
- Creation of KMS keys for S3, EBS, and RDS encryption
- Creation of variable files for the new account
- Updating the master configuration file with account metadata
- Generation of scripts to orchestrate the Terraform pipeline discussed below
- Sharing Transit Gateways via Resource Access Manager
Processing Account Terraform Pipeline
This pipeline manages the lifecycle of dynamic, frequently-updated resources, including IAM roles, S3 buckets and bucket policies, KMS key policies, security groups, NACLs, and bastion hosts.
There is one pipeline for every Processing Account, and each pipeline deploys a series of layers into the account, using a set of parameterized deployment jobs. A layer is a logical grouping of Terraform modules and AWS resources, providing a way to shrink Terraform state files and reduce blast radius if redeployment of specific resources is required.
EMR and SageMaker Deployment via Service Catalog
AWS Service Catalog facilitates the provisioning of Amazon EMR and Amazon SageMaker, allowing end users to launch EMR clusters and SageMaker notebook instances that work out of the box, with embedded security.
Service Catalog allows data scientists and data engineers to launch EMR clusters in a self-service fashion with user-friendly parameters, and provides them with the following:
- Bootstrap action to enable connectivity to services in Central Data Lake
- EC2 instance profile to control S3, KMS, and other granular permissions
- Security configuration that enables at-rest and in-transit encryption
- Configuration classifications for optimal EMR performance
- Encrypted AMI with monitoring and logging enabled
- Custom Kerberos connection to LDAP
For SageMaker, we use Service Catalog to launch notebook instances with custom lifecycle configurations that set up connections or initialize the following: Hive Metastore, Kerberos, security, Splunk logging, and OpenDNS. You can read more about lifecycle configurations in this AWS blog. Launching a SageMaker notebook instance with best-practice configuration is as easy as follows:

Conclusion
This post illustrates the building blocks we used in creating the Intuit Data Lake. Our solution isn’t wholly unique, but comprised of common-sense approaches we’ve gleaned from dozens of engineers across Intuit, representing decades of experience. These practices have enabled us to push petabytes of data into the lake, and serve hundreds of Processing Accounts with varying needs. We are still building, but we hope our story helps you in your data lake journey.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
 Michael Sambol is a senior consultant at AWS. He holds an MS in computer science from Georgia Tech. Michael enjoys working out, playing tennis, traveling, and watching Western movies.
Michael Sambol is a senior consultant at AWS. He holds an MS in computer science from Georgia Tech. Michael enjoys working out, playing tennis, traveling, and watching Western movies.
 Ben Covi is a staff software engineer at Intuit. At any given moment, he’s probably losing a game of Catan.
Ben Covi is a staff software engineer at Intuit. At any given moment, he’s probably losing a game of Catan.