AWS News Blog
New – Serverless Streaming ETL with AWS Glue

|
When you have applications in production, you want to understand what is happening, and how the applications are being used. To analyze data, a first approach is a batch processing model: a set of data is collected over a period of time, then run through analytics tools. To be able to react quickly, you can use a streaming model, where data is processed as it arrives, a record at a time or in micro-batches of tens, hundreds, or thousands of records.
Managing continuous ingestion pipelines and processing data on-the-fly is quite complex, because it’s an always-on system that needs to be managed, patched, scaled, and generally taken care of. Today, we are making this easier and more cost-effective to implement by extending AWS Glue jobs, based on Apache Spark, to run continuously and consume data from streaming platforms such as Amazon Kinesis Data Streams and Apache Kafka (including the fully-managed Amazon MSK).
In this way, Glue can provision, manage, and scale the infrastructure needed to ingest data to data lakes on Amazon S3, data warehouses such as Amazon Redshift, or other data stores. For example, you can store streaming data in a DynamoDB table for quick lookups, or in Elasticsearch to look for specific patterns. This procedure is usually referred to as extract, transform, load (ETL).
As you process streaming data in a Glue job, you have access to the full capabilities of Spark Structured Streaming to implement data transformations, such as aggregating, partitioning, and formatting as well as joining with other data sets to enrich or cleanse the data for easier analysis. For example, you can access an external system to identify fraud in real-time, or use machine learning algorithms to classify data, or detect anomalies and outliers.
Processing Streaming Data with AWS Glue
To try this new feature, I want to collect data from IoT sensors and store all data points in an S3 data lake. I am using a Raspberry Pi with a Sense HAT to collect temperature, humidity, barometric pressure, and its position in space in real-time (using the integrated gyroscope, accelerometer, and magnetometer). Here’s an architectural view of what I am building:
First, I register the device with AWS IoT Core, and run the following Python code to send, once per second, a JSON message with sensor data to the streaming-data MQTT topic. I have a single device in this setup, with more devices, I would use a subtopic per device, for example streaming-data/{client_id}.
import time
import datetime
import json
from sense_hat import SenseHat
from awscrt import io, mqtt, auth, http
from awsiot import mqtt_connection_builder
sense = SenseHat()
topic = "streaming-data"
client_id = "raspberrypi"
# Callback when connection is accidentally lost.
def on_connection_interrupted(connection, error, **kwargs):
print("Connection interrupted. error: {}".format(error))
# Callback when an interrupted connection is re-established.
def on_connection_resumed(connection, return_code, session_present, **kwargs):
print("Connection resumed. return_code: {} session_present: {}".format(
return_code, session_present))
if return_code == mqtt.ConnectReturnCode.ACCEPTED and not session_present:
print("Session did not persist. Resubscribing to existing topics...")
resubscribe_future, _ = connection.resubscribe_existing_topics()
# Cannot synchronously wait for resubscribe result because we're on the connection's event-loop thread,
# evaluate result with a callback instead.
resubscribe_future.add_done_callback(on_resubscribe_complete)
def on_resubscribe_complete(resubscribe_future):
resubscribe_results = resubscribe_future.result()
print("Resubscribe results: {}".format(resubscribe_results))
for topic, qos in resubscribe_results['topics']:
if qos is None:
sys.exit("Server rejected resubscribe to topic: {}".format(topic))
# Callback when the subscribed topic receives a message
def on_message_received(topic, payload, **kwargs):
print("Received message from topic '{}': {}".format(topic, payload))
def collect_and_send_data():
publish_count = 0
while(True):
humidity = sense.get_humidity()
print("Humidity: %s %%rH" % humidity)
temp = sense.get_temperature()
print("Temperature: %s C" % temp)
pressure = sense.get_pressure()
print("Pressure: %s Millibars" % pressure)
orientation = sense.get_orientation_degrees()
print("p: {pitch}, r: {roll}, y: {yaw}".format(**orientation))
timestamp = datetime.datetime.fromtimestamp(
time.time()).strftime('%Y-%m-%d %H:%M:%S')
message = {
"client_id": client_id,
"timestamp": timestamp,
"humidity": humidity,
"temperature": temp,
"pressure": pressure,
"pitch": orientation['pitch'],
"roll": orientation['roll'],
"yaw": orientation['yaw'],
"count": publish_count
}
print("Publishing message to topic '{}': {}".format(topic, message))
mqtt_connection.publish(
topic=topic,
payload=json.dumps(message),
qos=mqtt.QoS.AT_LEAST_ONCE)
time.sleep(1)
publish_count += 1
if __name__ == '__main__':
# Spin up resources
event_loop_group = io.EventLoopGroup(1)
host_resolver = io.DefaultHostResolver(event_loop_group)
client_bootstrap = io.ClientBootstrap(event_loop_group, host_resolver)
mqtt_connection = mqtt_connection_builder.mtls_from_path(
endpoint="a1b2c3d4e5f6g7-ats.iot.us-east-1.amazonaws.com",
cert_filepath="rapberrypi.cert.pem",
pri_key_filepath="rapberrypi.private.key",
client_bootstrap=client_bootstrap,
ca_filepath="root-CA.crt",
on_connection_interrupted=on_connection_interrupted,
on_connection_resumed=on_connection_resumed,
client_id=client_id,
clean_session=False,
keep_alive_secs=6)
connect_future = mqtt_connection.connect()
# Future.result() waits until a result is available
connect_future.result()
print("Connected!")
# Subscribe
print("Subscribing to topic '{}'...".format(topic))
subscribe_future, packet_id = mqtt_connection.subscribe(
topic=topic,
qos=mqtt.QoS.AT_LEAST_ONCE,
callback=on_message_received)
subscribe_result = subscribe_future.result()
print("Subscribed with {}".format(str(subscribe_result['qos'])))
collect_and_send_data()
This is an example of the JSON messages sent by the device:
{
"client_id": "raspberrypi",
"timestamp": "2020-04-16 11:33:23",
"humidity": 39.35261535644531,
"temperature": 30.10732078552246,
"pressure": 1020.447509765625,
"pitch": 4.044007304723748,
"roll": 7.533848064912158,
"yaw": 77.01560798660883,
"count": 104
}In the Kinesis console, I create the my-data-stream data stream (1 shard is more than enough for my workload). Back in the AWS IoT console, I create an IoT rule to send all data from the MQTT topic to this Kinesis data stream.
Now that all sensor data is sent to Kinesis, I can leverage the new Glue integration to process data as it arrives. In the Glue console, I manually add a table in the Glue Data Catalog. I select Kinesis as the type of source, and enter my stream name and the endpoint of the Kinesis Data Streams service. Note that for Kafka streams, before creating the table, you need to create a Glue connection.

I select JSON as data format, and define the schema for the streaming data. If I don’t specify a column here, it will be ignored when processing the stream.
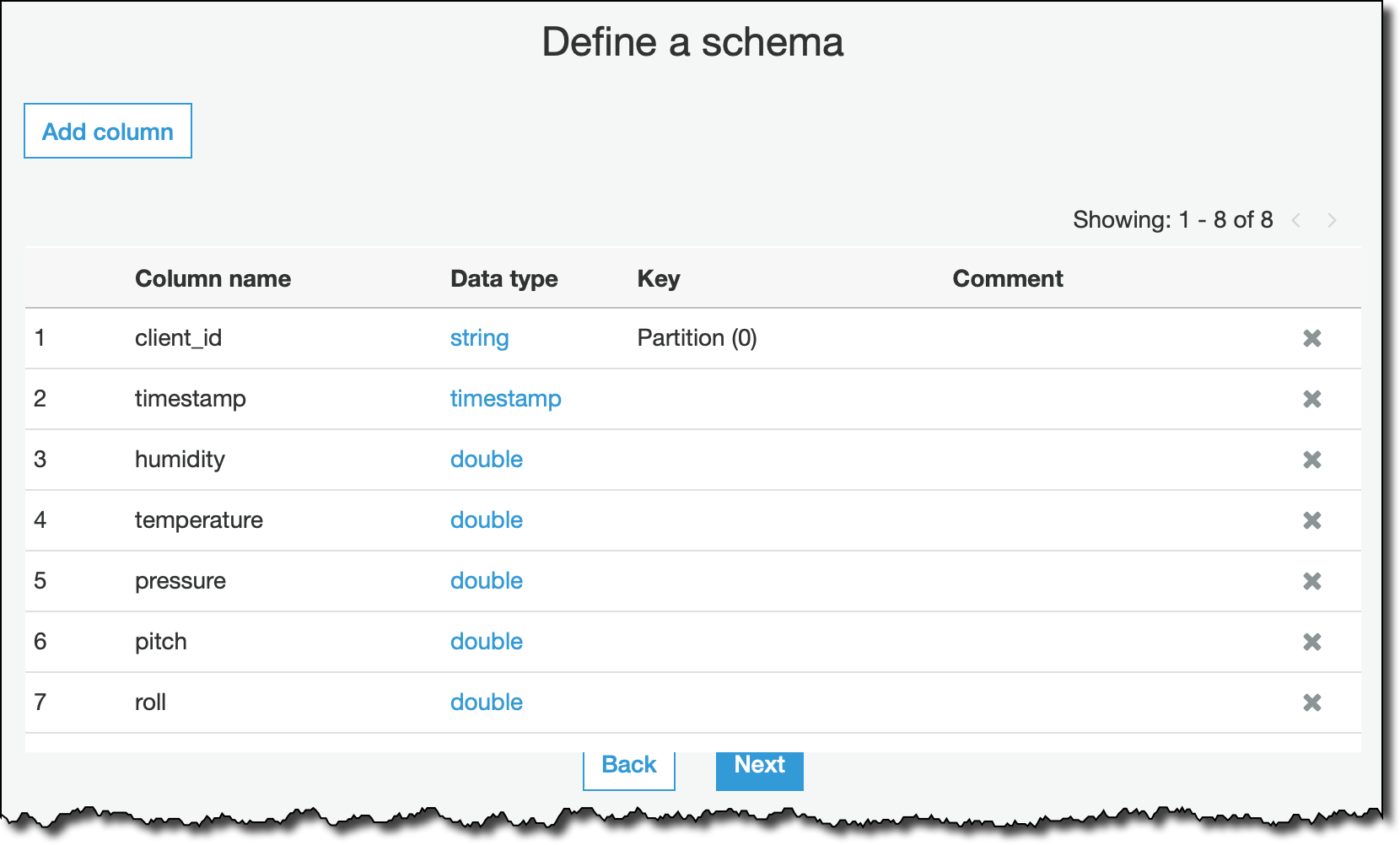
After that, I confirm the final recap step, and create the my_streaming_data table. We are working to add schema inference to streaming ETL jobs. With that, specifying the full schema up front won’t be necessary. Stay tuned.
To process the streaming data, I create a Glue job. For the IAM role, I create a new one attaching the AWSGlueServiceRole and AmazonKinesisReadOnlyAccess managed policies. Depending on your use case and the set up of your AWS accounts, you may want to use a role providing more fine-grained access.
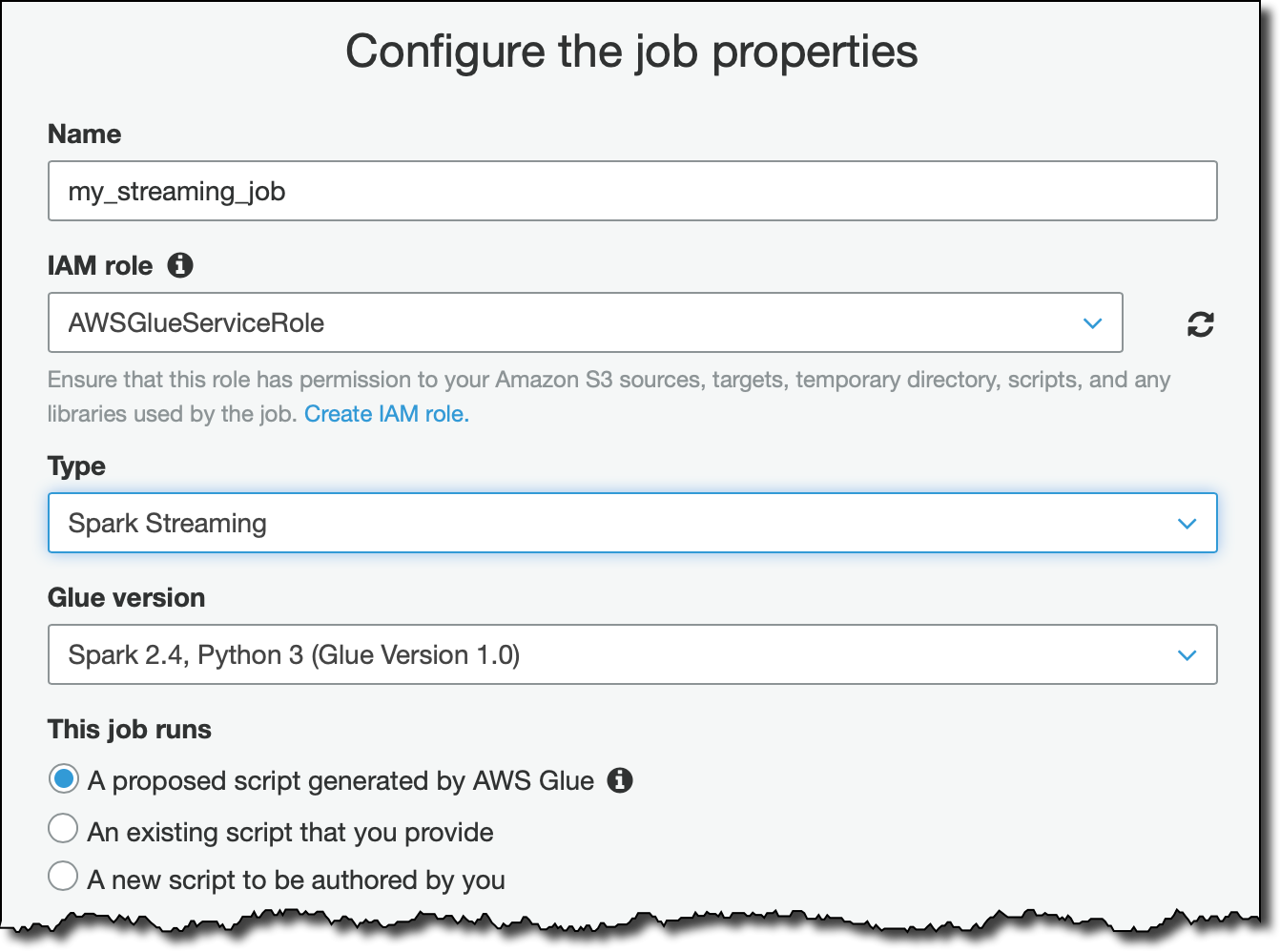
For the data source, I select the table I just created, receiving data from the Kinesis stream.

To get a script generated by Glue, I select the Change schema transform type. As target, I create a new table in the Glue Data Catalog, using an efficient format like Apache Parquet. The Parquet files generated by this job are going to be stored in an S3 bucket whose name starts with aws-glue- (including the final hyphen). By following the naming convention for resources specified in the AWSGlueServiceRole policy, this job has the required permissions to access those resources.
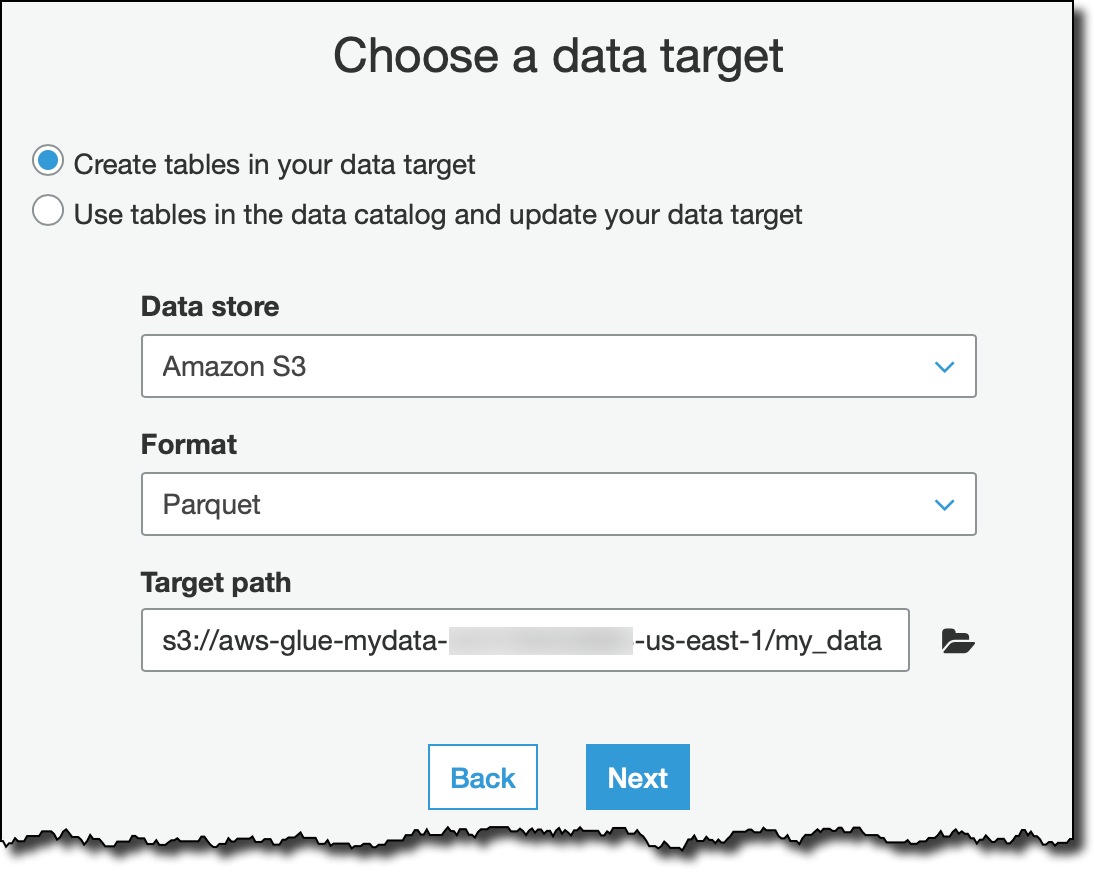
I leave the default mapping that keeps in output all the columns in the source stream. In this way, I can ingest all the records using the proposed script, without having to write a single line of code.

I quickly review the proposed script and save. Each record is processed as a DynamicFrame, and I can apply any of the Glue PySpark Transforms or any transforms supported by Spark Structured Streaming. By default with this configuration, only ApplyMapping is used.

I start the job, and after a few minutes I see the Parquet files containing the output of the job appearing in the output S3 bucket. They are partitioned by ingest date (year, month, day, and hour).
To populate the Glue Data Catalog with tables based on the content of the S3 bucket, I add and run a crawler. In the crawler configuration, I exclude the checkpoint folder used by Glue to keep track of the data that has been processed. After less than a minute, a new table has been added.
In the Amazon Athena console, I refresh database and tables, and select to preview the output_my_data containing ingest data from this year. In this way, I see the first ten records in the table, and get a confirmation that my setup is working!

Now, as data is being ingested, I can run more complex queries. For example, I can get the minimum and maximum temperature, collected from the device sensors, and the overall number of records stored in the Parquet files.
Looking at the results, I see more than 8,000 records have been processed, with a maximum temperature of 31 degrees Celsius (about 88 degrees Fahrenheit). Actually, it was never really this hot. Temperature is measured by these sensors very close to the device, and is growing as the device is warming up with usage.

I am using a single device in this set up, but the solution implemented here can easily scale up with the number of data sources.
Available Now
Support for streaming sources is available in all regions where Glue is offered, as described in the AWS Region table. For more information, please have a look at the documentation.
Managing a serverless ETL pipeline with Glue makes it easier and more cost-effective to set up and manage streaming ingestion processes, reducing implementation efforts so you can focus on the business outcomes of analytics. You can set up a whole ingestion pipeline without writing code, as I did in this walkthrough, or customize the proposed script based on your needs.
Let me know what are you going to use this new feature for!
— Danilo