AWS News Blog
AWS Batch for Amazon Elastic Kubernetes Service

|
Today I’m pleased to announce AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS). AWS Batch for Amazon EKS is ideal for customers who no longer want to shoulder the burden of configuring, fine-tuning, and managing Kubernetes clusters and pods to use with their batch processing workflows. Furthermore, there is no charge for this service. You only pay for the resources that your batch jobs launch.
When I’ve previously considered Kubernetes, it appeared to be focused on the management and hosting of microservice workloads. I was therefore surprised to discover that Kubernetes is also used by some customers to run large-scale, compute-intensive batch workloads. The differences between batch and microservice workloads mean that using Kubernetes for batch processing can be difficult and requires you to invest significant time in custom configuration and management to fine-tune a suitable solution.
Microservice and batch workloads on Kubernetes
Before we look further at AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS), let’s consider some of the important differences between batch and microservice workloads to help set some context on why running batch workloads on Kubernetes can be difficult:
- Microservice workloads are assumed to start and not stop—we expect them to be continuously available. In contrast, batch workloads run to completion and then exit—regardless of success or failure.
- The results from a batch workload might not be available for several minutes—and sometimes hours or even days. Microservice workloads are expected to respond to requests within milliseconds.
- We usually deploy microservice workloads across several Availability Zones to ensure high availability. This isn’t a requirement for batch workloads. Although we might distribute a batch job to allow it to process different input data in a distributed analysis, we more typically want to prioritize fast and optimal access to resources the job needs within the Availability Zone in which it is running.
- Microservice and batch workloads scale differently. For microservices, scaling is generally predictable and usually linear as load increases (or decreases). With batch workloads, you might first perform an initial, or infrequently repeated, proof-of-concept run to analyze performance and discover the correct tuning needed for a full production run. The difference in size between the two can be exponential. Furthermore, with batch workloads, we might scale to an extreme level for a run, then scale back to zero instances for long periods of time, sometimes months.
Although third-party frameworks can help with running batch workloads on Kubernetes, you can also roll your own. Whichever approach you take, significant gaps and challenges can remain in handling the undifferentiated heavy lifting of building, configuring, and maintaining custom batch solutions. Then you also need to consider the scheduling, placing, and scaling of batch workloads on Kubernetes in a cost-effective manner. So how does AWS Batch on Amazon Elastic Kubernetes Service (Amazon EKS) help?
AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS)
AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS) offers a fully managed service to run batch workloads using clusters hosted on Amazon Elastic Compute Cloud (Amazon EC2) with no need to install and manage complex, custom batch solutions to address the differences highlighted earlier. AWS Batch provides a scheduler that controls and runs high-volume batch jobs, together with an orchestration component that evaluates when, where, and how to place jobs submitted to a queue. There’s no need for you, as the user, to coordinate any of this work—you just submit a job request into the queue.
Job queueing, dependency tracking, retries, prioritization, compute resource provisioning for Amazon Elastic Compute Cloud (EC2) and Amazon Elastic Compute Cloud (EC2) Spot, and pod submission are all handled using a serverless queue. As a managed service, AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS) enables you to reduce your operational and management overhead and focus instead on your business requirements. It provides integration with other services such as AWS Identity and Access Management (IAM), Amazon EventBridge, and AWS Step Functions and allows you to take advantage of other partners and tools in the Kubernetes ecosystem.
When running batch jobs on Amazon Elastic Kubernetes Service (Amazon EKS) clusters, AWS Batch is the main entry point to submit workload requests. Based on the queued jobs, AWS Batch then launches worker nodes in your cluster to process the jobs. These nodes are kept separate in a distinct namespace from your other node groups in Amazon Elastic Kubernetes Service (Amazon EKS). Similarly, nodes in other pods are isolated from those used with AWS Batch.
How it works
AWS Batch uses managed Amazon Elastic Kubernetes Service (Amazon EKS) clusters, which need to be registered with AWS Batch, and permissions set so that AWS Batch can launch and manage compute environments in those clusters to process jobs submitted to the queue. You can find instructions on how to launch a managed cluster that AWS Batch can use in this topic in the Amazon Elastic Kubernetes Service (Amazon EKS) User Guide. Instructions for configuring permissions can be found in the AWS Batch User Guide.
Once one or more clusters have been registered, and permissions set, users can submit jobs to the queue. When a job is submitted, the following actions take place to process the request:
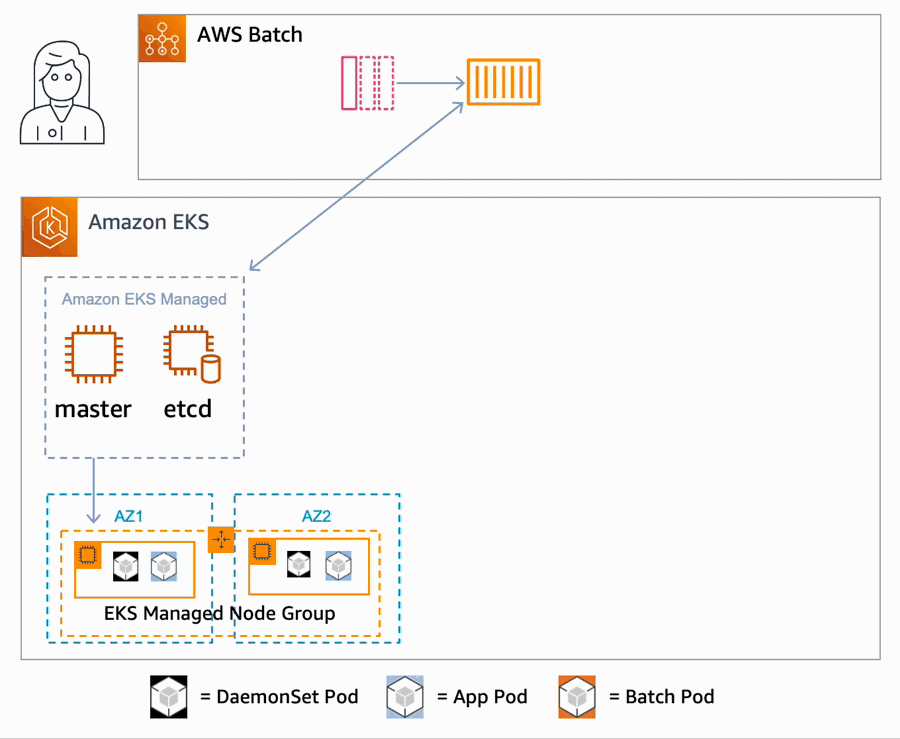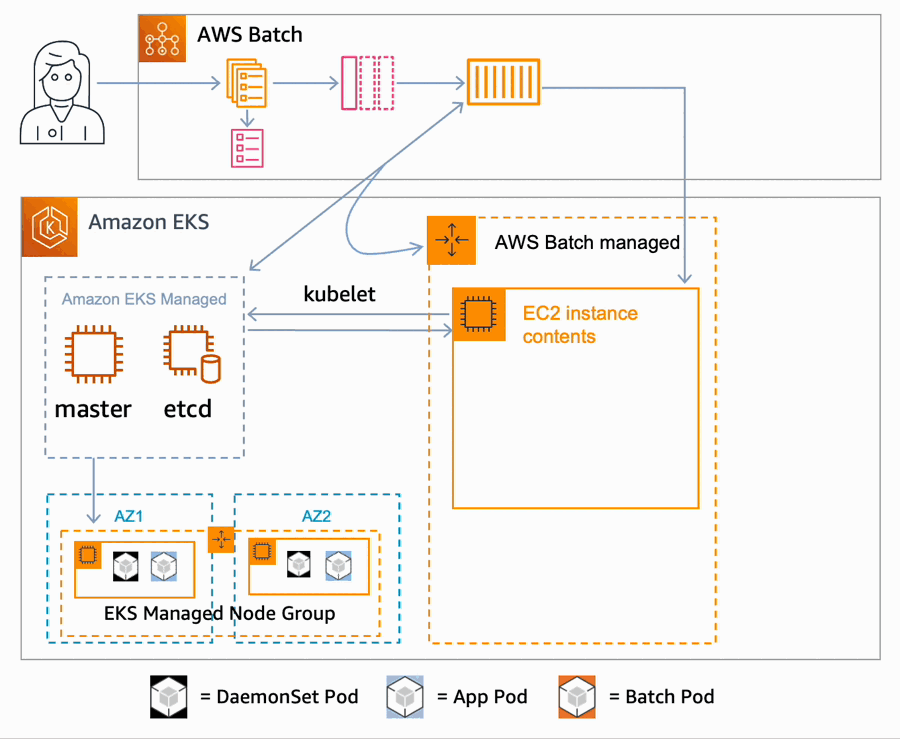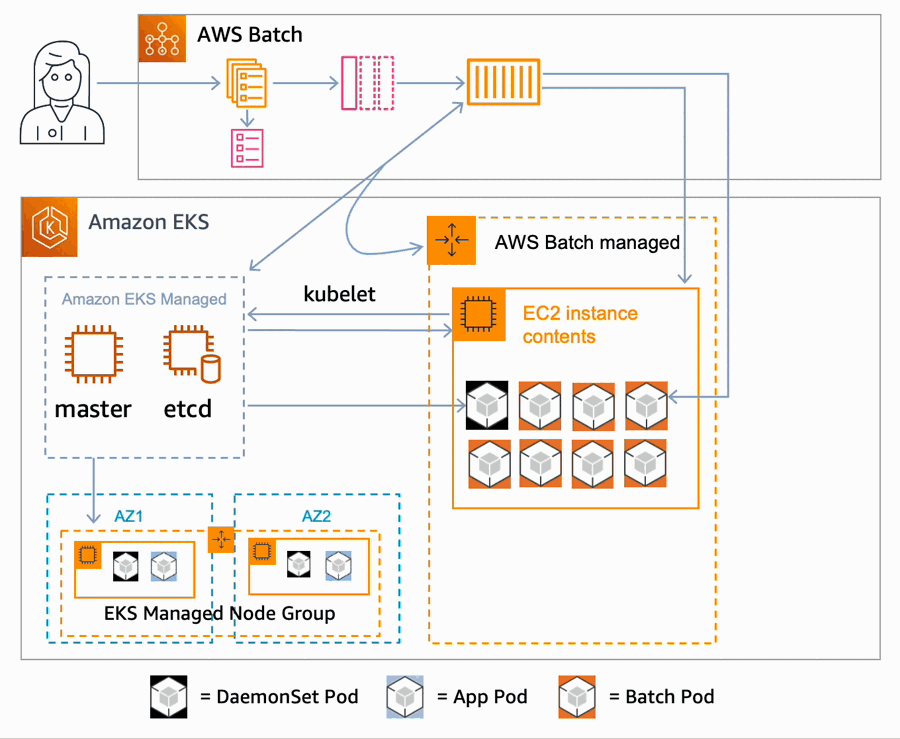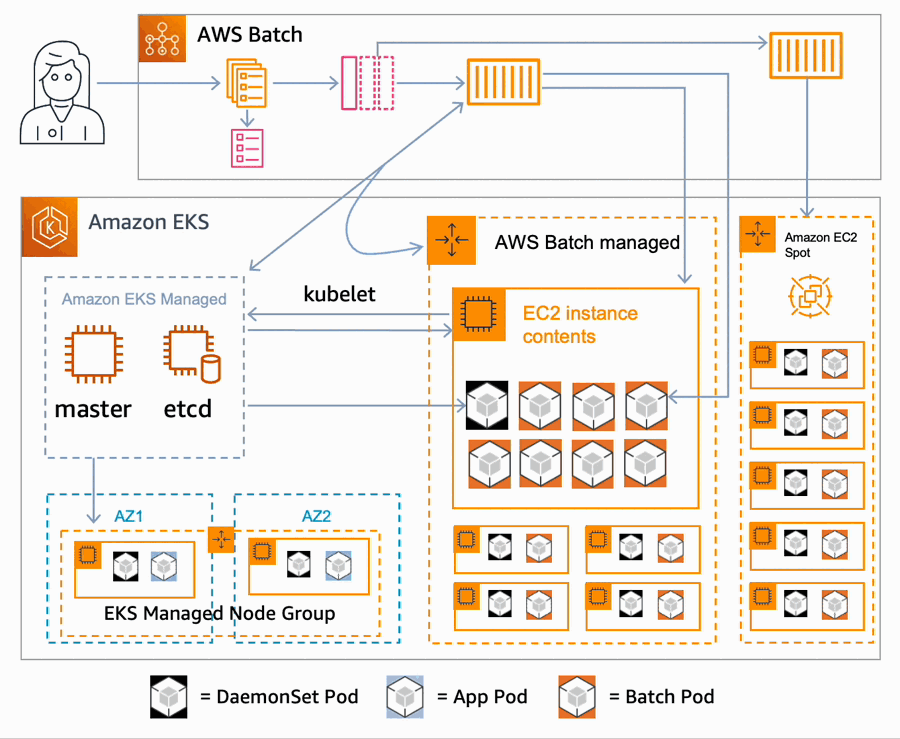
- On receiving a job request, the queue dispatches a request to the configured compute environment for resources. If an AWS Batch managed scaling group does not yet exist, one is created, and AWS Batch then starts launching Amazon Elastic Compute Cloud (EC2) instances in the group. These new instances are added to the AWS Batch Kubernetes namespace of the cluster.
- The Kubernetes scheduler places any configured DaemonSet on the node.
- Once the node is ready, AWS Batch starts sending pod placement requests to your cluster, using labels and taints to make the placement choices for the pods, bypassing much of the logic of the k8s scheduler.
- This process is repeated, scaling as needed across more EC2 instances in the scaling group until the maximum configured capacity is reached.
- If the job queue has another compute environment defined, such as one configured to use Spot instances, it will launch additional nodes in that compute environment.
- Once all work is complete, AWS Batch removes the nodes from the cluster, and terminates the instances.
These steps are illustrated in the animation below.
Start using your clusters with AWS Batch today
AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS) is available today. As I noted earlier, there is no charge for this service, and you pay only for the resources your jobs consume. To learn more, visit the Getting Started with Amazon Elastic Kubernetes Service (Amazon EKS) topic in the AWS Batch User Guide. There is also a self-guided workshop to help introduce you to AWS Batch on Amazon Elastic Kubernetes Service (Amazon EKS).