AWS Architecture Blog
Field Notes: Create a Serverless Live-to-VOD Workflow with AWS Elemental
Many of our customers in the entertainment industry are transforming their business structure from a traditional broadcasting model to a digital media and online content distribution platform. Many shows and sport events are streamed live online and users expect to be able to catch up and rewatch content immediately after it airs. This demand creates the need for a robust and cost effective way to set up Live-to-VOD pipelines at scale.
In this post, we show how to easily set up a serverless pipeline using AWS Elemental Media Services. This serverless pipeline will help create and manage a Live-to-VOD application that allows users to extract video clips from a live stream, and then automatically process and prepare those clips for discovery in a VOD library. This solution is completely serverless, and costs are driven by resource consumption— a stark contrast to traditional solutions driven by fixed costs and upfront investments.
The Live Streaming on AWS solution of the AWS Solutions Library is a vetted pattern that creates a streaming video workflow using an encoder in the AWS Cloud to produce adaptive bitrate (ABR) content, and a packager to deliver the ABR streams to one or more viewers—including mobile devices and desktop browsers. We use this workshop as a basis and extend it to automate the Live-to-VOD workflow.
This solution consists of two major components: Video Delivery and VOD Application as shown in the following reference architecture diagram.
- Video Delivery encapsulates services that are required to provide a livestream and extract clips from the live signal.
- VOD Application encompasses components that are required to automate the workflow for creating clips and making them accessible via an API.
Let’s get started!
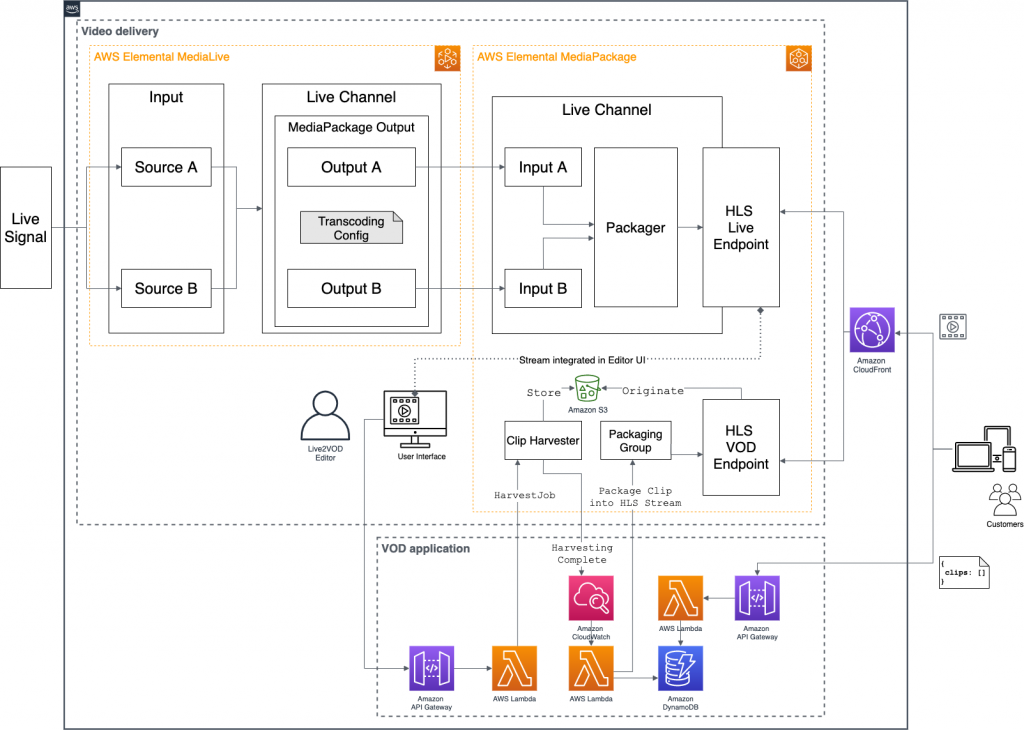
Figure 1 – Architecture of the complete Live-to-VOD solution
Video delivery
The first step in building our Live-to-VOD application is deploying the Live Streaming on AWS solution into your account, which will set up all services and configurations required to provide an HLS packaged live stream. In this blog post, we describe the two AWS Elemental services we use to transcode and package the video signal.
Transcoding video with AWS Elemental MediaLive
The first challenge we face is to process the uncompressed live signal in real time into formats suitable for online streaming. For this, we use AWS Elemental MediaLive, a broadcast-grade live video processing service. It lets you create high-quality video streams for delivery to broadcast televisions and internet-connected multiscreen devices, like connected TVs, tablets, smartphones, and set-top boxes. The service encodes your live video streams in real time, taking a larger-sized live video source and compressing it into smaller versions for distribution to your viewers.
In this solution demo, AWS Elemental MediaLive takes an uncompressed video, encodes it in real time and sends the compressed video downstream to AWS Elemental MediaPackage for packaging. In most real world applications, your input comes from a live feed originating from an uncompressed live source like HD-SDI and requires more processing steps (that is, onsite transcoding using appliances like AWS Elemental Live), but in this simplified demo we use a static video file in Amazon S3 on loop as our live signal.
ABR packaging with AWS Elemental MediaPackage
After compressing the video stream, we must package it for delivery to our customers. AWS Elemental MediaPackage reliably prepares and protects your video for delivery over the internet. From a single video input, AWS Elemental MediaPackage creates video streams formatted to play on connected TVs, mobile phones, computers, tablets, and game consoles.
In this solution demo, we use AWS Elemental MediaPackage to package our compressed video signal into an Adaptive Bitrate (ABR) stream using HTTP Live Streaming (HLS). AWS Elemental MediaPackage supports all common video streaming formats, but for this solution we focus on HLS and out scope other features like AdMarkers or Digital Rights Management (DRM). At the end of the processing pipeline, we get an HTTP endpoint for the HLS manifest and are able to stream our video in any player that supports HLS.
Packaging group
After deploying the CloudFormation stack from the Live Streaming on AWS solution, we have everything necessary to provide a scalable and fault-tolerant enterprise-grade live-stream.
The next step is to set up a packaging group in AWS Elemental MediaPackage, which we will use to prepare the extracted clips for our VOD library. A packaging group holds one or more packaging configurations and defines the outputs that are available for the assets the packaging group is associated with.
The following snippet shows how a basic HLS packaging configuration can be setup using the AWS SDK for Python (boto).
To operationalize this, we recommend adapting the initial AWS CloudFormation template so that this is automatically provisioned during the deployment.
def create_hls_packaging_group(group_id,
hls_packaging_config_id):
mediapackage_vod.create_packaging_group(Id=group_id)
mediapackage_vod.create_packaging_configuration(
HlsPackage={
'HlsManifests': [
{
'AdMarkers': 'NONE',
'ManifestName': 'index',
'ProgramDateTimeIntervalSeconds': 60,
},
],
'SegmentDurationSeconds': 6,
'UseAudioRenditionGroup': True
}
,
Id=hls_packaging_config_id,
PackagingGroupId=group_id
)After creating the packaging group, we have everything set up in the Video Delivery component and can continue with the VOD application.
VOD application
The VOD application encompasses all components that are required to automate the workflow of creating clips and making them accessible via an API. In a real world scenario, the application could also contain a static website that integrates a video player to play the live stream we created earlier in the demo. This website would call an API that invokes a Lambda function, which triggers the extraction of a clip in AWS Elemental MediaPackage.
For brevity, in this solution demo we omit the webpage and focus on the API that triggers the process of clip extraction. We acknowledge that in a real world application, a clip would typically be created based on a dynamically set time interval, but for this demo we instead create a clip of the last 60 seconds of the livestream every time the API is called.
We use the AWS Serverless Application Model (AWS SAM) to manage all resources of the VOD application and the AWS SDK for Python(Boto) in our code. The following snippets show how to instantiate the required modules of the SDK and how to set up the environment variables we use in our Lambda functions.
import boto3
mediapackage = boto3.client('mediapackage')
mediapackage_vod = boto3.client('mediapackage-vod')
dynamodb = boto3.resource('dynamodb')Globals:
Function:
Runtime: python3.7
Environment:
Variables:
CLIPS_TABLE: !Ref ClipsTable
CLIPS_BUCKET: !Ref ClipsBucket
CLIPS_ORIGIN_ENDPOINT_ID: !Ref ClipsOriginEndpointId
PACKAGING_GROUP_ID: !Ref PackagingGroupId
MEDIA_PACKAGE_S3_ROLE_ARN: !GetAtt MediaPackageS3Role.ArnExtracting clips from the live stream with job harvesting
To extract clips from our live stream we use an AWS Elemental MediaPackage feature called job harvesting, which allows us to extract a clip from a live stream by providing the id of the corresponding endpoint, a start and end time for the clip, and an S3 bucket to store the created clip.
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. It integrates well with Amazon API Gateway, a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
The following code defines an AWS Lambda function that creates a harvest job every time a POST request is sent to the /api/clip route of the created API Gateway. This harvest job will:
- Create a clip with an end date of
nowand a start date ofnow - 60 s - Use
CLIPS_ORIGIN_ENDPOINT_IDas source endpoint for this clip - Tell AWS Elemental MediaPackage to assume the
MEDIA_PACKAGE_S3_ROLE_ARNrole in order to be allowed to write the clip to Amazon S3 (CLIPS_BUCKET)
def create_new_clip(event):
clip_end = int(time.time())
clip_start = clip_end - 60
clip_id = f"{clip_start}_{clip_end}"
mediapackage.create_harvest_job(
StartTime=clip_start,
EndTime=clip_end,
Id=clip_id,
OriginEndpointId=CLIPS_ORIGIN_ENDPOINT_ID,
S3Destination={
'BucketName': CLIPS_BUCKET,
'ManifestKey': f"{clip_id}.m3u8",
'RoleArn': MEDIA_PACKAGE_S3_ROLE_ARN
}
)
return {
"statusCode": 200,
"headers": {
'Content-Type': 'application/json'
}
}
CreateNewClipWithHarvestJob:
Type: 'AWS::Serverless::Function'
Properties:
Handler: handler.create_new_clip
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action: 'mediapackage:*'
Resource: "*"
Events:
Apigateway:
Type: Api
Properties:
Path: '/api/clip'
Method: POSTPackaging and publishing a clip
The final step before we can offer our clip to our users is to package and publish it. Because creating a clip via harvest job is an asynchronous process, we use Amazon CloudWatch to send an alert when the job completes. Every time a harvesting job completes, a CloudWatch Event with details about the job is logged. This allows us to create a CloudWatch Events Rule that reacts on this event by invoking another Lambda function with the details of this event.
The following YAML code for AWS SAM describes both an Events Rule and a Lambda function and sets up the permissions that allow the Events Rule to trigger the Lambda Function.
ProcessHarvestedClip:
Type: 'AWS::Serverless::Function'
Properties:
Handler: handler.process_harvested_clip
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action: 'mediapackage-vod:*'
Resource: "*"
- Effect: Allow
Action: 'iam:PassRole'
Resource: "*"
- Effect: Allow
Action: 'dynamodb:PutItem'
Resource: !GetAtt ClipsTable.Arn
EventRule:
Type: AWS::Events::Rule
Properties:
Description: "HarvestJobToLambdaEventRule"
EventPattern:
source:
- "aws.mediapackage"
detail-type:
- "MediaPackage HarvestJob Notification"
State: "ENABLED"
Targets:
- Arn: !GetAtt ProcessHarvestedClip.Arn
Id: "HarvestJobLambda"
PermissionForEventsToInvokeLambda:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref ProcessHarvestedClip
Action: "lambda:InvokeFunction"
Principal: "events.amazonaws.com"
SourceArn: !GetAtt EventRule.ArnThis configuration ensures that our Lambda function is invoked anytime a new clip has been harvested and provides the necessary information to process the request. For our use case, we keep it simple and only deal with succeeded jobs (if harvest_job['status'] == "SUCCEEDED" ).
At this point, two more steps are required to make the clips available in a VOD library.
- Create a video asset out of the harvested clip
An asset holds all of the information that AWS Elemental MediaPackage requires to ingest file-based video content from a source such as Amazon S3. Through the asset, AWS Elemental MediaPackage ingests and dynamically packages content in response to play back requests.
We require three pieces of information to create an asset.
- The
Idof the packaging group that we created earlier. This tells AWS Elemental MediaPackage the parameters it needs to create an ABR stream. - The
SourceArn, which tells us where to find the manifest of the created clips. This information is part of the payload the Lambda is invoked with by the Events Rule. - The
SourceRoleArn, which like in the previous steps is a reference to a role that allows the AWS Elemental MediaPackage service to read data from theSourceArnbucket on our behalf.
2. Persist the clip metadata in a database
We gather this information and persist the clip metadata to allow users to discover clips in their apps. We use Amazon DynamoDB, a fully managed key-value and document database that delivers single-digit millisecond performance at any scale. As we have a well-understood access pattern that can be modeled as key-value lookups, Amazon DynamoDB is a great fit that also integrates well with AWS Lambda.
There are two things to consider when thinking about the design of our DynamoDB Table.
- A feature that is important in a real world scenario is keeping context between
create_harvest_jobandprocess_harvested_clip, for example to add custom metadata like title or description of a clip. In our demo, this is context is not kept due to the asynchronous nature of the workflow. An easy way to solve this is to insert the clip into the database already in thecreate_harvest_jobstep, flag it as inactive, and then activate it after the harvest job has successfully finished. - When creating a table, we have to choose a partition key that has a high cardinality and spreads out clip metadata across many partitions. For this example, we assume that each clip can be associated with a live event and that many such events happen in parallel (that is, Olympic Games with many different competitions), thus making the
competitionIda good partition key. As we used timestamps for theclipId, we can use them to query clips related to a certain event. Although we will not dive deeper into this topic, it is important to consider DynamoDB table design before transferring this solution into a production application.
These design decisions are reflected in the following YAML code for AWS SAM that describes the table and puts it into auto scaling mode (BillingMode: PAY_PER_REQUEST). We also must give ProcessHarvestedClip permissions for the putItem operation on this particular table, which we did in the Policies section when we created the Lambda function.
ClipsTable:
Type: 'AWS::DynamoDB::Table'
Properties:
AttributeDefinitions:
- AttributeName: competition
AttributeType: S
- AttributeName:
AttributeType: S<
KeySchema:
- AttributeName: competition
KeyType: HASH
- AttributeName: clip
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
TableName: "VOD-Clips"def process_harvested_clip(event):
table = dynamodb.Table(CLIPS_TABLE)
harvest_job = event['detail']['harvest_job']
destination_bucket_name =
harvest_job['s3_destination']['bucket_name']
manifest_key =
harvest_job['s3_destination']['manifest_key']
if harvest_job['status'] == "SUCCEEDED":
asset = mediapackage.create_asset(
Id=harvest_job['id'],
PackagingGroupId=PACKAGING_GROUP_ID,
SourceArn=f"arn:aws:s3:::{destination_bucket_name}/{manifest_key}",
SourceRoleArn=MEDIA_PACKAGE_S3_ROLE_ARN
)
table.put_item(Item={
"competition": COMPETITION_ID,
"clip": asset['Id'],
"meta": {
"id": asset['Id'],
"title": f"Clip: {asset['Id']}"
},
"manifests": asset['EgressEndpoints']
})Our clip harvesting workflow is now complete and will create a clip, package it, and add its metadata and manifests (asset.EgressEndpoints) to our DynamoDB table (CLIPS_TABLE) for every call made to the /api/clip endpoint.
Clip API
After implementing the clipping workflow, we are ready to build an API that allows our users to discover and watch clips.
We use Amazon API Gateway and AWS Lambda again to implement a customer-facing RESTful web service that provides a route to retrieve all clips of a given competitionId. The frontend devices of our users query this endpoint to retrieve all clips for the 100-m dash, including all metadata and the URL of the manifest.
GET https://someurl.com/api/competitions/100m-dash/clips
{
"clips": [
{
"competition": "100m-dash",
"manifest": "https://abcdef.egress.mediapackage-vod.eu-central-1.amazonaws.com/out/v1/../index.m3u8",
"clip": "20200203133058_20200203133258",
"meta": {
"title": "First race",
"description": "Someone wins",
"id": "20200203133058_20200203133258"
}
},
{
..
}
]
}- We must create a Lambda function that is invoked via a RESTful web service and is allowed to query our DynamoDB table.
- We must add our business logic to the Lambda function, which in this case is a query that gets all clips for a given competition. We can utilize the
clipIdfor time-based queries (“clips of the last 24 hours”, etc.) or add global secondary indexes to the table as needed.
Lambda Function
def get_all_clips_for_competition(event):
competition_id =
event['pathParameters']['competitionId']
table = dynamodb.Table(CLIPS_TABLE)
clips = table.query(
KeyConditionExpression='competition = :id',
ExpressionAttributeValues={
':id': competition_id
}
)
return {
"statusCode": 200,
"body": json.dumps(clips.get('Items', []))
}AWS SAM
GetAllVotes:
Type: 'AWS::Serverless::Function'
Properties:
Handler: handler.getAllClipsForCompetition
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- 'dynamodb:Query'
Resource: !GetAtt ClipsTable.Arn
Events:
Apigateway:
Type: Api
Properties:
Path: '/api/competitions/{competitionId}/clips'
Method: GETWe can now deploy our VOD Application and start creating clips for our VOD library. Check the GitHub repo for the complete source code and more detailed instructions.
Summary
In this blog post, we built a serverless video delivery pipeline that allows us to take a live video signal as input, transcode the signal in real time, and then output an adaptive bitrate stream (ABS). We also created a workflow that allows us to extract clips from the live stream and automatically put them into a VOD library, with no human interaction beyond the point of triggering the clip creation process required.
Achieving just the basic functionality of what we managed to provide in a few hundred lines of code requires a significant investment in an on-premises setup. The solution we created requires zero upfront investment and only incurs costs for the actual usage, since we do not have to pay for idle resources when no event happening and no users are watching. From a resiliency standpoint, the solution has built in redundancy by running the video delivery pipeline in two Availability Zones and utilizing serverless computing in the VOD application. If you also take operational complexity, low utilization, and limited scalability into account, it becomes even more apparent why many of AWS’ media customers consider these new capabilities a game changer for their business.
The deployment of the solution is automated using infrastructure as code, which makes it maintainable and repeatable. Scaling the application is easy, both from a Video Delivery and a VOD Application perspective. For the former, we may adapt our automation to handle additional live signals and integrate with the clipping components by creating additional video delivery pipelines. Scaling with user demand is inherently covered as well, since AWS Lambda, Amazon DynamoDB and Amazon API Gateway are serverless offerings that allow customers to offload the complexity of scaling to those services.
Clean up
The solution this demo builds is not covered by our free tier and will incur costs based on consumption. Be sure to clean up both the Live Streaming on AWS solution and the stack you created as part of this blog post. This ensures you are not billed for any accidental consumption of resources you created.