AWS Architecture Blog
Category: Storage

Serverless architecture for optimizing Amazon Connect call-recording archival costs
In this post, we provide a serverless solution to cost-optimize the storage of contact-center call recordings. The solution automates the scheduling, storage-tiering, and resampling of call-recording files, resulting in immediate cost savings. The solution is an asynchronous architecture built using AWS Step Functions, Amazon Simple Queue Service (Amazon SQS), and AWS Lambda. Amazon Connect provides an […]

Identification of replication bottlenecks when using AWS Application Migration Service
Enterprises frequently begin their journey by re-hosting (lift-and-shift) their on-premises workloads into AWS and running Amazon Elastic Compute Cloud (Amazon EC2) instances. A simpler way to re-host is by using AWS Application Migration Service (Application Migration Service), a cloud-native migration service. To streamline and expedite migrations, automate reusable migration patterns that work for a wide […]

Running hybrid Active Directory service with AWS Managed Microsoft Active Directory
Enterprise customers often need to architect a hybrid Active Directory solution to support running applications in the existing on-premises corporate data centers and AWS cloud. There are many reasons for this, such as maintaining the integration with on-premises legacy applications, keeping the control of infrastructure resources, and meeting with specific industry compliance requirements. To extend […]

Detecting data drift using Amazon SageMaker
As companies continue to embrace the cloud and digital transformation, they use historical data in order to identify trends and insights. This data is foundational to power tools, such as data analytics and machine learning (ML), in order to achieve high quality results. This is a time where major disruptions are not only lasting longer, […]

Building a serverless cloud-native EDI solution with AWS
Electronic data interchange (EDI) is a technology that exchanges information between organizations in a structured digital form based on regulated message formats and standards. EDI has been used in healthcare for decades on the payer side for determination of coverage and benefits verification. There are different standards for exchanging electronic business documents, like American National […]

Dream11: Blocking application attacks using AWS WAF at scale
As the world’s largest fantasy sports platforms with more than 120 million registered users, Dream11 runs multiple contests simultaneously while processing millions of user requests per minute. Their user-centric and data-driven teams make it a priority to ensure that the Dream11 application (app) remains protected against all kinds of threats and vulnerabilities. Introduction to AWS […]

Migration updates announced at re:Invent 2021
re:Invent is a yearly event that offers learning and networking opportunities for the global cloud computing community. 2021 marks the launch of several new features in different areas of cloud services and migration. In this blog, we’ll cover some of the most important recent announcements. AWS Mainframe Modernization (Preview) Mainframe modernization has become a necessity […]
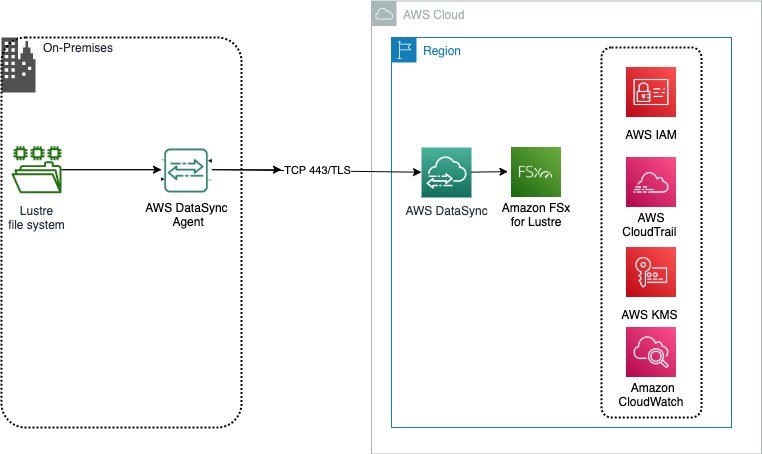
Migrating petabytes of data from on-premises file systems to Amazon FSx for Lustre
For International Women’s Day and Women’s History Month, we’re featuring more than a week’s worth of posts that highlight female builders and leaders. We’re showcasing women in the industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech. Many organizations use the Lustre filesystem for Linux-based applications that […]

Extend SQL Server DR using log shipping for SQL Server FCI with Amazon FSx for Windows configuration
For International Women’s Day and Women’s History Month, we’re featuring more than a week’s worth of posts that highlight female builders and leaders. We’re showcasing women in the industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech. Companies choosing to rehost their on-premises SQL Server workloads to […]

Disaster recovery approaches for Db2 databases on AWS
As you migrate your critical enterprise workloads from an IBM Db2 on-premises database to the AWS Cloud, it’s critical to have a reliable and effective disaster recovery (DR) strategy. This helps the database applications operate with little or no disruption from unexpected events like a natural disaster. Recovery point objective (RPO), recovery time objective (RTO), […]