AWS Partner Network (APN) Blog
Healthier Data and Trusted Insights with Collibra Data Quality on AWS
By Milind Pandit, Director, Professional Services – Collibra
By Dilip Rajan, Manager, Partner Solutions Architect – AWS
 |
| Collibra |
 |
We know that data can help organizations get closer to customers and unlock new revenue streams. But in order to monetize data, companies need to be able to trust it.
Trust comes from organizing and governing data, but it also comes from managing and monitoring the quality of data so everyone can easily find, understand, and reliably use it.
Collibra Data Intelligence Cloud helps organizations build trust in data across any source, for any user. Core to this solution is Collibra Data Quality (DQ) on Amazon Web Services (AWS), which enables organizations to get the added benefit of cloud-scale combined with a rich set of features that:
- Deliver real-time visibility into the health of data.
- Minimize the time it takes to resolve data issues.
- Reduce the cost of migrating data to the cloud.
In this post, we’ll take a look at how Collibra DQ is architected on AWS. Organizations can additionally use this joint solution to automate data discovery with monitoring and alerting, so they can easily build healthier data pipelines.
Collibra is an AWS Partner with the Financial Services Competency and leader in data governance, helping organizations across the world gain competitive advantage by maximizing the value of their data.
Collibra Data Quality on AWS
Before we dive in, let’s take a quick look at the key features of Collibra DQ:
- Explorer: A no-code option to get started quickly and onboard a dataset.
- Profile (automatic): Create profiles based on a table, view, or file.
- Behaviors: Does your data behave/look/feel the same way it has in the past (a few columns or rows dropped)?
- SQL-based rules engine: Assures only values compliant with your data rules are allowed within a data object.
- Duplicates: Fuzzy matching to identify entries that have been added multiple times with similar but not exact detail.
- Schema: When columns are added or dropped.
- Shapes: Typos and formatting anomalies.
- Outliers: Anomalous records, clustering, time-series, categorical data points that differ significantly from other observations.
- Pattern: Recognizing relevant classification, cross-column and parent/child anomalies between data examples.
- Record: Deltas for critical data elements in a given column(s).
- Source: Source to target reconciliation.
- Pushdown: Generate SQL queries to offload the compute to the data source, reducing the amount of data transfer and Spark computation of the DQ job.
Reference Architecture
Next, let’s move to Collibra DQ’s architecture on AWS and how it can be deployed.

Figure 1 – Collibra DQ reference architecture.
The Collibra DQ reference architecture provides a common vocabulary, reusable designs, and industry best practices to accelerate delivery of an effective DQ solution.
Collibra Control Plane
- DQ web instance: A 2-4GB Amazon Elastic Compute Cloud (Amazon EC2) instance to support an interactive user interface (UI), interaction between users and Collibra DQ, and a robust set of APIs for automated integration.
- DQ metastore: Amazon Relational Database Service (Amazon RDS) PostgreSQL database to support persistence of metadata, statistics, and results. It’s the main point of communication between web instances and DQ agents in the customer data plane. Metastore also contains the results of the DQ jobs performed between transient workers.
Customer Data Plane
- DQ agent: Creates a technical descriptor of the work that needs to be done and then launches the job.
- Amazon EMR on Apache Spark (master/task nodes): Executes DQ jobs through Apache Spark to run data quality on terabyte scale datasets.
AWS Storage or JDBC Data Sources
Collibra DQ supports the below sources for both data preview as well DQ check operations:
- Native AWS sources: Collibra DQ supports JDBC sources such as Amazon Athena, Amazon Redshift, Amazon RDS, and Amazon Simple Storage Service (Amazon S3).
- Partner data sources: Other supported data sources on AWS include Snowflake, Databricks delta lake, and Teradata.
How to Perform a Data Quality Check
Typically, data quality checks are scheduled to run on a given dataset daily. Mostly, a data quality check consists of four steps: connection, exploration, execution, and reporting.
Step 1: Configure a Connection
To configure a connection, Collibra DQ needs to access data from an underlying data source where it can perform its data quality operations; for that, it can connect to any database with a JDBC connector.
After providing the connection settings under Admin, you’ll want to Save the connection settings. For a list of comprehensive and supported data connections, refer to the documentation.
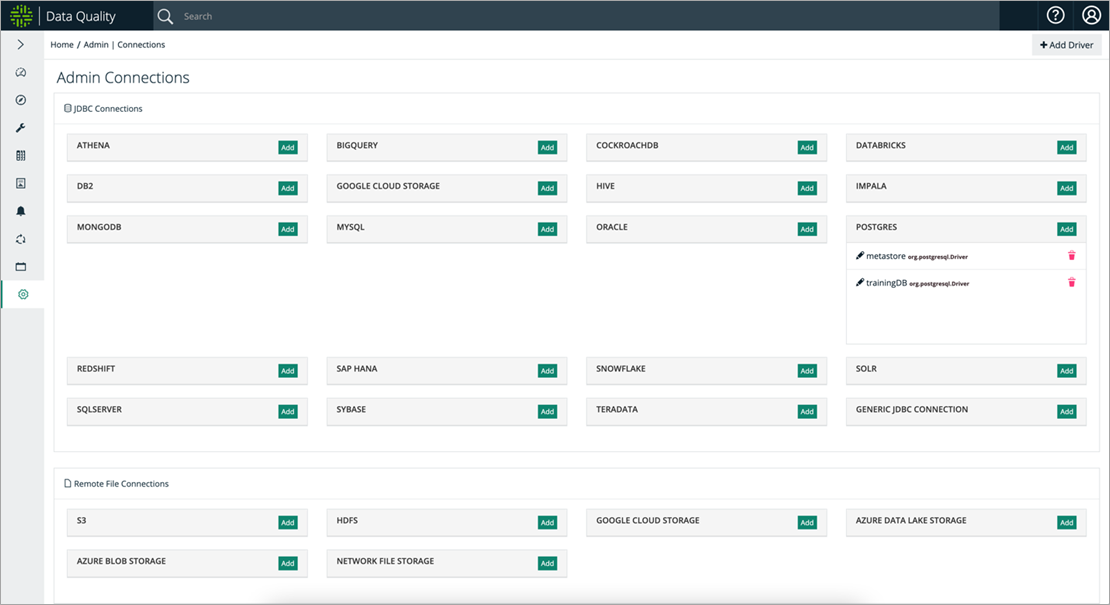
Figure 2 – Setting up a connection.
Step 2: DQ Job Setup
Under Connections Explorer, select a schema/table in the table explorer. A DQ check wizard is automatically created on the right-hand side. After selecting all the default options, click Run to execute a data quality check.
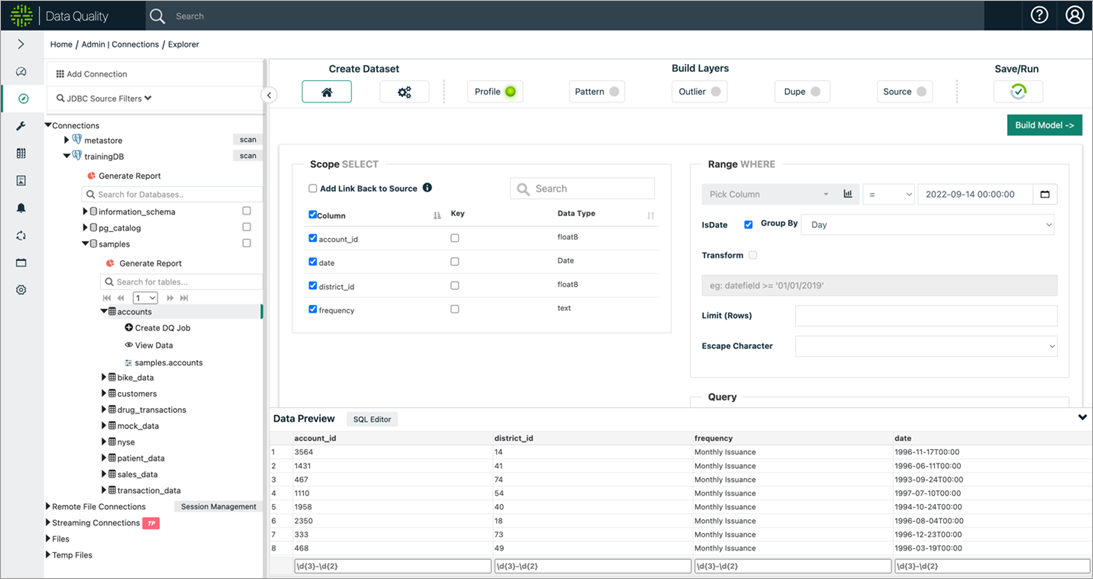
Figure 3 – Creating a DQ check job.
Step 3: Job Status Details
During the run execution, DQ logs are pulled from the compute instances to give the live status of the execution of the job. Additionally, job details are available, as shown in the following figure through the jobs folder.

Figure 4 – Job status details.
Step 4: DQ Results
The DQ check alerts the user for any data quality issues. For example, in the figure below, email ID and postal code columns have encountered data issues, as an email ID with single character email domain name is invalid.

Figure 5 – Summary of DQ results.
While inspecting the same table below, you can see that columns can be masked and auto-labeled as personally identifiable information (PII) and material non-public information (MNPI) for SSN_Number.

Figure 6 – Deep dive into DQ results.
The above labeling and data quality checks are performed using Collibra DQ by leveraging advancements in data science and machine learning (ML) instead of manual rules, thus reducing the cost of managing these datasets at scale.
Operations on large datasets are compute-intensive, and for Collibra DQ customers have a choice of deployment options and appropriate best practices.
Let’s take a look at those now.
Deployment Options
Collibra DQ can be deployed in three ways:
- Standalone install
- This deployment, which is available through AWS Marketplace, is a single node deployment available as a trial option.
- It uses the install script for a standard install.
- Deploy with Spark on yarn (Amazon EMR).
- Cloud-native deployment with Amazon Elastic Kubernetes Service (Amazon EKS) and Helm chart.
Best Practices
The following best practices ensure you get the best out of your Collibra DQ on AWS:
- Set up a strong foundation: Create a well-defined use case for the proposed solution, defining the success criteria and the expectations from Collibra DQ. Study the data quality standards in your organization defined by your data governance team, and assess how you will meet them.
. - Implement Fit-for-Purpose DQ: Deploy the fully distributed DQ architecture with the right capacity planning. Onboard the dataset by running a simple profile first. Add a Date (${rd}) to the select query to make this a time series check for end-to-end data observability across pipelines.
.
Run the job 5-7 times on good sample data to form the baseline, understand the output, and stabilize the Collibra DQ check. Automatically uncover data drift, outliers, patterns, and schema changes, and add them to Collibra DQ Scan.
.
Set up sensitive data discovery by adding the data category/data classification and reviewing the findings. Add business rules not discovered via the automated rules. Set up scorecards based on your business model, organized by line of business, storage, schema, or data ownership.
. - Drive enterprise DQ adoption: Collibra DQ is designed for collaboration for enterprise-wide continuous data quality improvements. You can leverage the unified scoring system, scorecards, and built-in reports to simplify reporting and alerts to all stakeholders. The Collibra DQ API-based integration within your data pipelines enables dynamic discussion based on DQ scores.
Conclusion
Collibra Data Quality is available on AWS Marketplace as an Amazon Machine Image (AMI), and can get you started in a matter of minutes.
We have described how Collibra DQ leverages AWS infrastructure to crunch through large data volumes allowing customers to evaluate their data quality without allocating funding towards a capital expense towards on-premises infrastructure. So, explore the AWS and Collibra DQ trial and get your organization on the path to trusted data.
.

.
Collibra – AWS Partner Spotlight
Collibra is an AWS Competency Partner and leader in data governance, helping organizations across the world gain competitive advantage by maximizing the value of their data.